오늘의 노래 추천
- 아티스트
- Green Day
- 앨범
- American Idiot (Deluxe)
- 발매일
- 1970.01.01
DAY 1
ㅡ request 라이브러리 ㅡ
jupyter notebook 사용

requests 의 get, post 등의 메서드를 사용해 데이터를 받아오고
text 메서드를 이용해 응답받은 데이터를 문자열 형태로 출력
ㅡ BeautifulSoup 라이브러리 ㅡ
jupyter notebook 사용
from bs4 import BeautifulSoup as bs
# BeautifulSoup 객체화
# bs(parsing할 html 문서(문자열형태), 'parsing할 방법')
# lxml : 빠르고 관대하다는 특징
soup = bs(res.text, 'lxml')
html 문서에서 원하는 데이터를 추출하기 쉽게 해주는 라이브러리
문자열 형태가 아닌 파이썬이 읽기 쉬운 객체 형태로 변환
ㅡ 네이버 크롤링 실습 ㅡ
카테고리 명 가져오기
블로그, 카페, 이미지 등의 글자 데이터를 가져와보자
url = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query='
res = req.get(url)
soup = bs(res.text, 'lxml')
requests, BeatifulSoup 라이브러리로 데이터 받아오기

select : page의 모든 a태그가 전부 list 형태로 응답
select_one : page의 a태그 중 첫번째 요소 하나만 응답
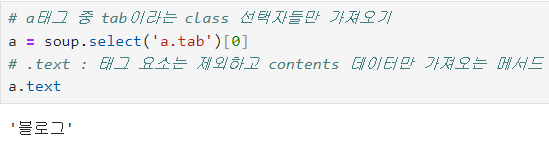
# a태그 중 tab이라는 class 선택자들만 가져오기
a = soup.select('a.tab')[0]
# .text : 태그 요소는 제외하고 contents 데이터만 가져오는 메서드
a.text
선택자 기호와 text 메서드를 활용해 contents 데이터 가져오기
ㅡ 네이버 날씨 크롤링 실습 ㅡ
현재 온도 가져오기
url = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=%EB%82%A0%EC%94%A8'
res = req.get(url)
soup = bs(res.text, 'lxml')
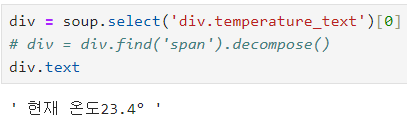
div = soup.select('div.temperature_text')[0]
# div = div.find('span').decompose()
div.text
ㅡ melon top 100 데이터 가져오기 실습 ㅡ
Response [406] 오류
부적절한 요청 차단 오류
웹사이트가 특정한 요청 헤더가 없거나 올바르지 않을 때 접근을 차단하는 설정
User-Agent 값 headers 설정
# 멜론에서 컴퓨터 접근을 막고있기 때문에 -> 우회 접속 User-Agent 설정
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
res = req.get('https://www.melon.com/chart/index.htm', headers=headers)
soup = bs(res.text, 'lxml')
개발자 모드 network 탭에서 f5를 누르고 맨위의 html 문서형태 ( type : document ) 클릭
맨 아래의 User-Agent 를 복사해서 dictionary 형태로 선언
ㅡ> headers 부분에 dictionary 형태 변수 추가
for i in range(100):
title = soup.select('div.ellipsis.rank01')[i].text.strip()
singer = soup.select('span.checkEllipsis')[i].text.strip()
# 데이터 전처리 (개행문자 제거)
# 앞 뒤 공백 제거 함수 : strip()
print(title, singer)
for 문을 이용해 데이터 수집
ㅡ 리스트에 데이터를 넣고 DataFrame 형태로 출력해보기 ㅡ
# 반복문 실습
# 1. 공간 생성(빈 리스트 생성)
# 2. 컨텐츠를 인덱스 번호로 하나씩 추출
# 3. 데이터 정제
# 4. 리스트에 하나씩 쌓기
top100 = []
for i in range(100):
title = soup.select('div.ellipsis.rank01')[i].text.strip()
singer = soup.select('span.checkEllipsis')[i].text.strip()
# 데이터 전처리 (개행문자 제거)
# 앞 뒤 공백 제거 함수 : strip()
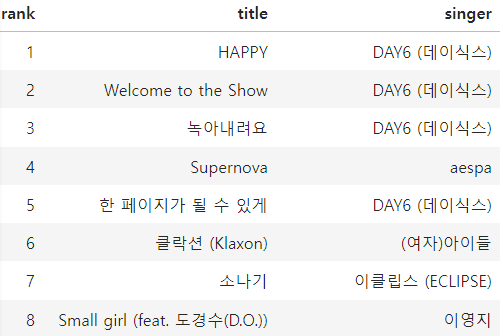
top100.append({"rank" : i+1, "title" : title, "singer" : singer})

import pandas as pd
top100_df = pd.DataFrame(top100)
top100_df = top100_df.style.hide(axis='index')
top100_df
데이터 프레임 형태로 출력
# csv 형태로 내보내기
top100_df.to_csv('MelonChart.csv', encoding='euc-kr')
csv 형태로 내보내기
ㅡ 페이지 변환 리뷰 데이터 크롤링 실습 ( 바디럽 페이지 ) ㅡ
페이지를 변환해가며 많은 양의 데이터 수집
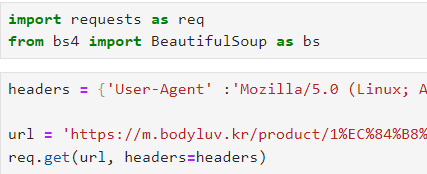
라이브러리 import 및 데이터 불러오기
* iframe 태그
화면에는 존재하는 것처럼 보이지만 실제 데이터는 다른 서버에 존재하는 경우
iframe 태그 자체의 메모리가 너무 크고 크롤링에 방해가 되기 때문에 안 쓰는 추세
ㅡ> 실제 데이터가 저장되어 있는 iframe 주소로 찾아가서 크롤링 해줘야함
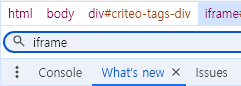
f12 개발자 도구에서 ctrl+f 로 iframe 태그를 찾고 src 속성값이 바로 iframe 주소
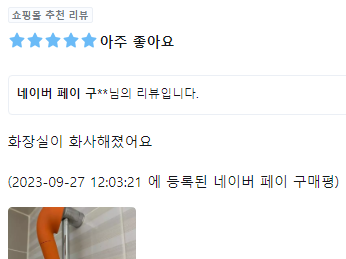
'네이버 페이 구매평'은 순수 리뷰 데이터가 아니므로 제거하기
naverReview = review[0].text.strip()
if '네이버 페이 구매평' in naverReview:
# 슬라이싱을 통해 접근
naverReview = naverReview[:-38]
naverReview
ㅡ 페이지를 넘기면서 모든 리뷰 데이터 크롤링 ㅡ
for 반복문 활용
reviewList = []
for j in range(1, 20):
url = f'https://review4.cre.ma/bodyluv.kr/products/reviews?app=0&iframe=1&iframe_id=crema-product-reviews-2&install_method=hardcoded&page={j}&parent_url=https%3A%2F%2Fbodyluv.kr%2Fproduct%2F1%25EC%2584%25B8%25EB%258C%2580-%25ED%2593%25A8%25EC%2596%25B4%25EC%258D%25B8-%25EC%25BB%25AC%25EB%259F%25AC-%25EC%2583%25A4%25EC%259B%258C%25EA%25B8%25B0%2F601%2Fcategory%2F1%2Fdisplay%2F2%2F%23prdReview&product_code=601&secure_device_token=V2d871d83121e9bf8b25306090e9198973e96ab9bc21bd4750f0bdab3f05ff9e39834ae8ee1de86bf83b07ab08c484f1d4&widget_env=100&widget_style=list#'
res = req.get(url)
soup = bs(res.text, 'lxml')
pageReview = soup.select('div.review_list_v2__message.js-collapsed-review-content.js-translate-text')
for i in range(len(pageReview)):
review = pageReview[i].text.strip()
if '네이버 페이 구매평' in review:
# 슬라이싱을 통해 접근
review = review[:-38]
reviewList.append({"i" : i+1, "review" : review})
review_df = pd.DataFrame(reviewList)
review_df.set_index('i', inplace=True)
review_df
이중 for 문을 사용해 페이지를 넘기고 페이지 별 모든 리뷰 데이터 가져오기
*tqdm을 설치해서 로딩시간 확인 가능
ㅡ selenium 라이브러리 ㅡ
페이지를 변환해가며 많은 양의 데이터 수집
# selenium 내장 라이브러리가 아니므로 다운해야함
!pip install selenium
!pip install -U selenium
!pip install webdriver_manager
# 라이브러리 불러오기
from selenium import webdriver as wb
# 웹브라우저 제어를 위한 라이브러리
from selenium.webdriver.common.by import By
# html 문서에서 태그와 선택자의 위치를 찾기위한 라이브러리
from selenium.webdriver.common.keys import Keys
# 웹에게 값을 입력하기위한 라이브러리
from selenium.webdriver.chrome.service import Service
# 사용자가 사용하는 최신버전의 크롬 드라이버와 일치하는 드라이버를 찾아주는 라이브러리
from webdriver_manager.chrome import ChromeDriverManager
# 최신버전의 크롬 드라이버를 찾고 다운해주는 라이브러리
필요한 라이브러리 import
ㅡ 웹 브라우저 제어로 크롬창 열기 ㅡ
# ChromeDriverManager().install() : 크롬 드라이버 업데이트 및 설치
s = Service(ChromeDriverManager().install())
wb.Chrome(service = s)
ㅡ url 주소 지 ㅡ
# ChromeDriverManager().install() : 크롬 드라이버 업데이트 및 설치
s = Service(ChromeDriverManager().install())
driver = wb.Chrome(service = s)
# 주소를 알려주지 않으면 빈 창이 뜨므로
# requests 에서 처럼get 메서드를 사용해 페이지의 url 입력
driver.get('https://www.naver.com/')
ㅡ 검색창 찾고 검색어 입력 ㅡ
# 검색창 위치 찾고 검색어 입력하기
# send_keys('단어') : 해당 '단어'라는 키워드를 전송
search = driver.find_element(By.ID, 'query')
search.send_keys('아이유 배경화면')
ㅡ ENTER 기능 실행 or 검색 버튼 클릭 ㅡ
# 키보드 enter 기능 사용
# search.send_keys(Keys.ENTER) : 엔터 기능 실행
search.send_keys(Keys.ENTER)
# 검색버튼 클릭
searchBtn = driver.find_element(By.ID, 'search-btn')
searchBtn.click() # 클릭 메서드
ㅡ 창 닫기 ㅡ
# 크롬창 닫기
driver.close()
(수정중)

BYE
'크롤링' 카테고리의 다른 글
| 크롤링 DAY2 ( ) (0) | 2024.09.25 |
|---|