오늘의 노래 추천 🌃
- 아티스트
- Red Velvet (레드벨벳)
- 앨범
- Cosmic
- 발매일
- 2024.06.24
birthday 랑 feel my rhythm 섞은 느낌나요
참고 : 본인 레드벨벳 최애곡 birthday ㅡ> 진심개좋다는뜻
- 아티스트
- Red Velvet (레드벨벳)
- 앨범
- Cosmic
- 발매일
- 1970.01.01
이것도 좋음 타이틀곡 후보였대요 팡 터지는 맛이 있는 곡 꼭 들어야함!!
DAY 8
[ Pandas ]
pandas library

1차원 데이터는 '시'리즈 ( 첫글자 대문자 )
인덱스 + 값
2차원 데이터는 '데'이터 프레임 ( 첫글자 대문자 )
표와 같은 형태
ㅡ pd.Series

ㅡ Series 값 확인 ㅡ

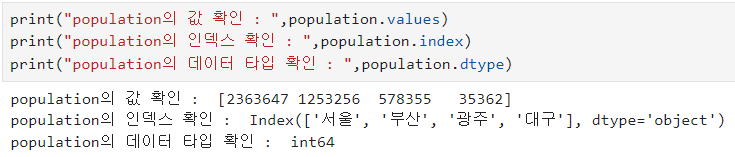

인덱스 이름 달기
.index.name
.name
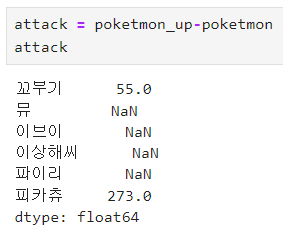
ㅡ Series 연산 ㅡ
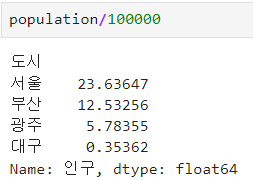
Series 에 바로 연산자를 사용해 연산가능

Series 끼리의 연산, NaN 값 출력
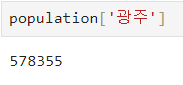
ㅡ Series 인덱싱 ㅡ

index 번호 또는 index 값으로 인덱싱 가능함
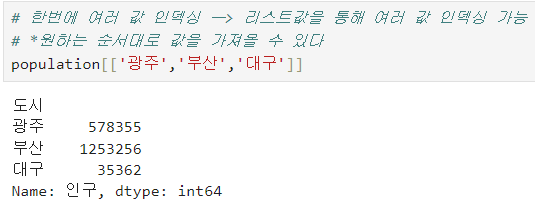
"리스트"를 통해 한번에 여러 값 인덱싱 가능함
* 원하는 순서대로 값을 불러올 수 있음
ㅡ Series Boolean 인덱싱 ㅡ

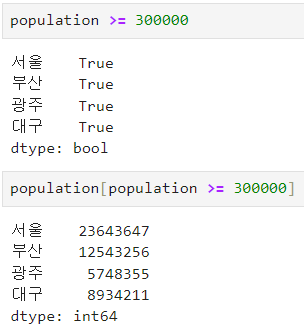

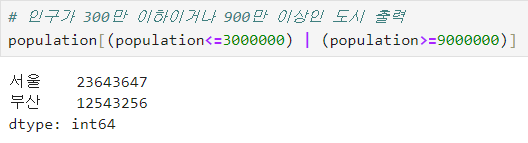
소괄호와 & 또는 | 연산자로 두 가지 이상의 조건을 이어줌
ㅡ Series 슬라이싱 ㅡ
위치 기반 접근
레이블 기반 접근
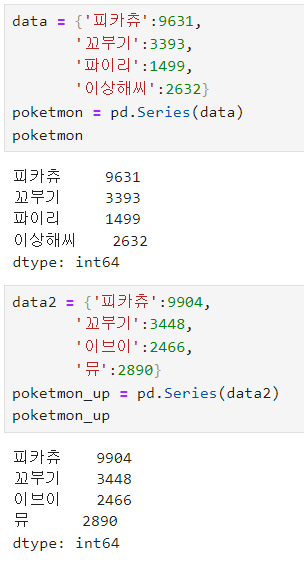
* ( List 가 아닌 ) Dictionary 객체를 이용한 Series 생성

key 값과 value 값으로 구성된 dictionary 에서
key 값은 Series 의 index, value 값은 value 값이 된다

dictionary 형태로 만든 데이터를 data 변수에 넣어주고
data 를 pd.Series 타입의 population2 에 넣어줌
[ dictionary 객체 Series 실습 ]
ㅡ notnull, isnull
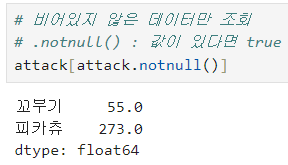


ㅡ Series 값 갱신, 추가, 삭제 ㅡ

대입 연산자 이용
[ DataFrame ]
pandas library
dictionary 사용
* value에 해당하는 요소를 리스트로 묶어줘야함


ㅡ DataFrame 인덱스 수정 ㅡ
df.index

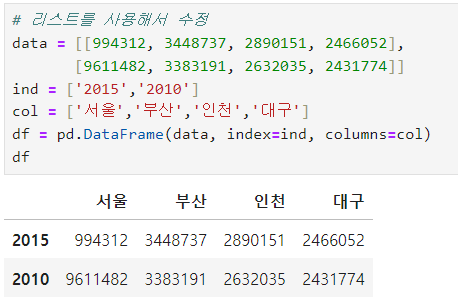
ㅡ DataFrame 인덱스 지정하여 생성 ㅡ
리스트 이용
ㅡ DataFrame column 와 index바꾸기 ㅡ
.T

출력만 진행되고 원래 값은 재대입이 필요함
ㅡ DataFrame 값 확인 ㅡ
.values .index .columns


ㅡ DataFrame 열 생성 / 수정 ㅡ
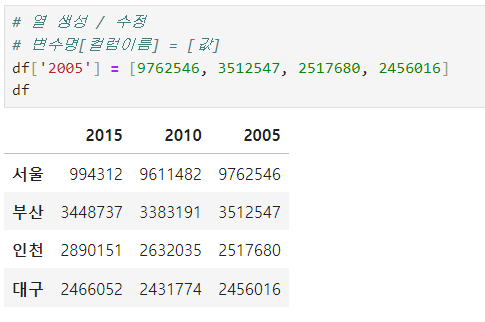
대입 연산자를 이용해 열 생성
변수명 [ 컬럼이름 ] = [ 값 ]
[ DataFrame 인덱싱 슬라이싱 ]

ㅡ DataFrame 열 인덱싱 ㅡ
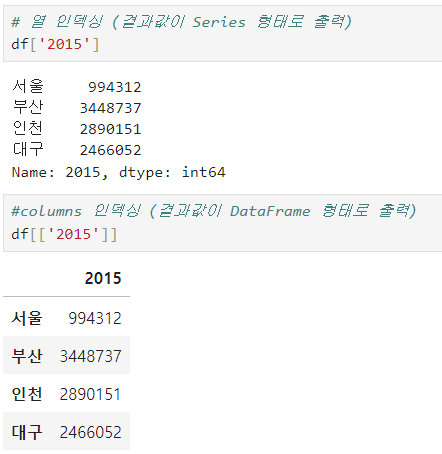
방법에 따라 결과가 각각 Series, DataFrame 으로 출력됨
ㅡ DataFrame 행 인덱싱 ㅡ

위치 기반 접근 ( 인덱스 번호 )
레이블 기반 접근 ( 인덱스 값 )
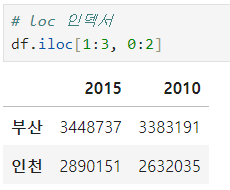
ㅡ loc[], iloc[] 인덱서 ㅡ
loc, iloc ( 레이블, 위치 )

loc []
실제 인덱스 값을 사용해 행을 가지고 올 때 사용 (레이블 기반 접근)

iloc []
numpy 의 array 인덱싱 방식으로 행을 가지고 올 때 ( 위치 기반 접근 )
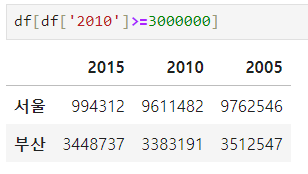
ㅡ DataFrame Boolean 인덱싱 ㅡ
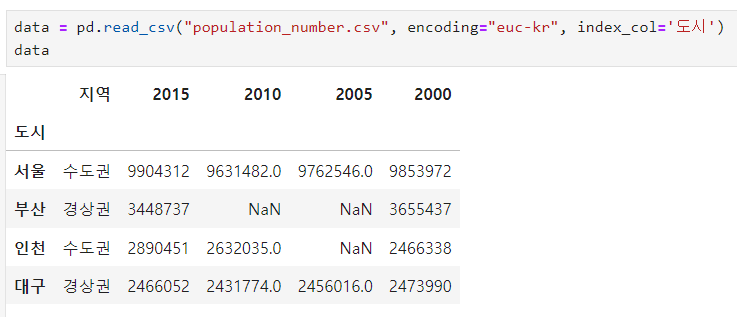
[ csv 파일 불러오기 ]
ㅡ read csv ㅡ
.value_counts ()
값이 숫자, 문자열, 카테고리 값인 경우에 각각의 값이 나온 횟수를 셀 수 있음
.tail ()
뒷 5개 데이터 확인 가능


ㅡ 정렬 ㅡ
sort
.sort_index ()
'인덱스 값'을 기준으로 정렬 ( 오름차순 )
.sort_values ()
'데이터 값'을 기준으로 정렬 ( 오름차순 )
* by 를 이용한 컬럼 값 지정이 필요할 수 있음
*ascending = False
내림차순

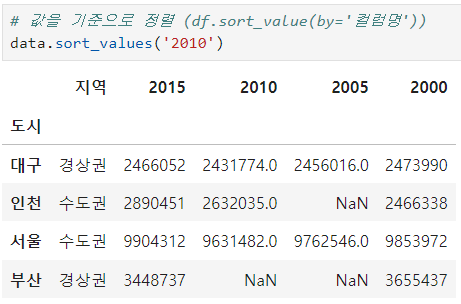
by 는 생략가능
* 여러 컬럼 조건을 통한 정렬
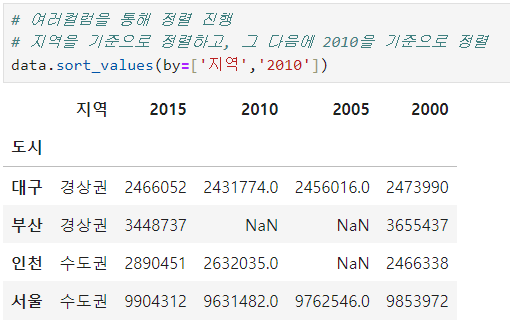
[ 최종 실습 ]
ㅡ csv 파일불러오기
read.csv
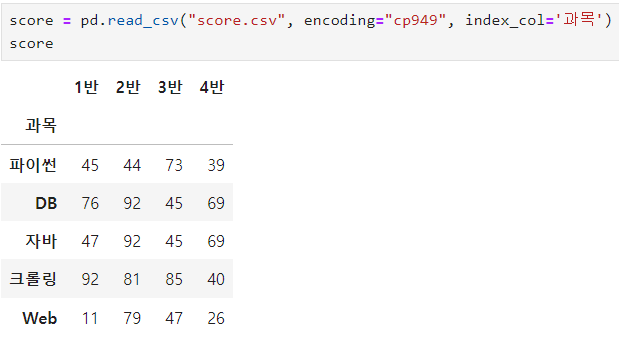
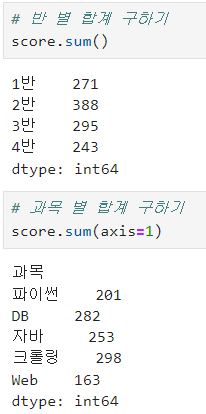
ㅡ 합계 구하기
sum
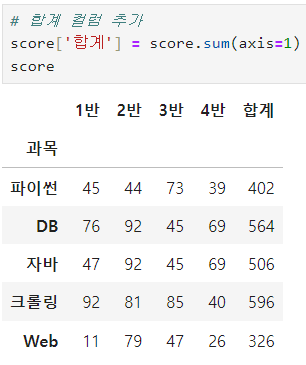
ㅡ 합계 컬럼 추가
sum
ㅡ 평균 구하기
mean

ㅡ 반 평균 구하기
mean ( axis = 0 )

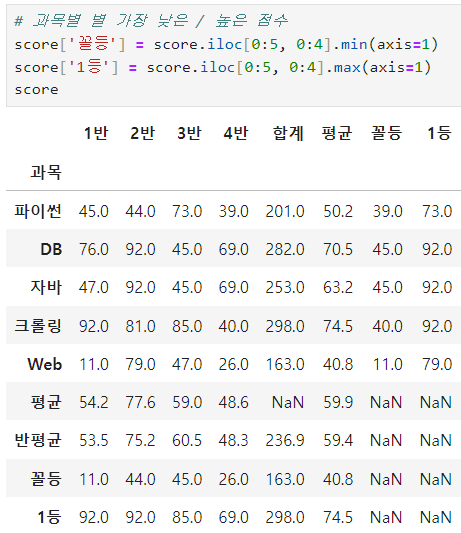
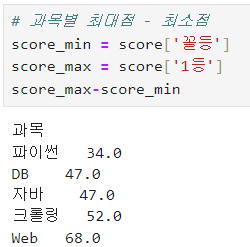
ㅡ 최대 최솟값 구하기
min, max ( axis = 1 )
ㅡ apply ( func, axis =0 or 1 )
mean ( axis = 0 )
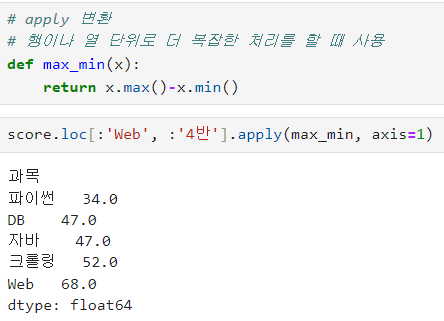
행이나 열 단위로 더 복잡한 처리를 할 때 사용
[ category ]

ㅡ 카테고리 만들기
pd.cut ()

카테고리에 들어갈 데이터
카테고리를 분류할 기준이 되는 범주
카테고리 명칭
ㅡ> 리스트 형태의 값으로 작성
ㅡ 카테고리만 보고 싶을 때
.categories

ㅡ 카테고리만 보고 싶을 때
.categories
ㅡ 카테고리만 보고 싶을 때
.categories

ㅡ 카테고리만 보고 싶을 때
.categories

[ DataFrame 병합 ]
ㅡ Merge ()
특정 컬럼을 기준으로 병합
pd.merge ( df1, df2, on = 중복컬럼명, how = 조인방식 )
inner : 중복값이 있는 행만 출력 ( 교집합방식 )
left : 왼쪽 df 에 있는 값은 모두 출력
right : 오른쪽 df 에 있는 값은 모두 출력
full Outer : 존재하는 값 모두 출력
ㅡ 데이터 dictionary 생성

ㅡ DataFrame 에 dictionary 값 넣어주기
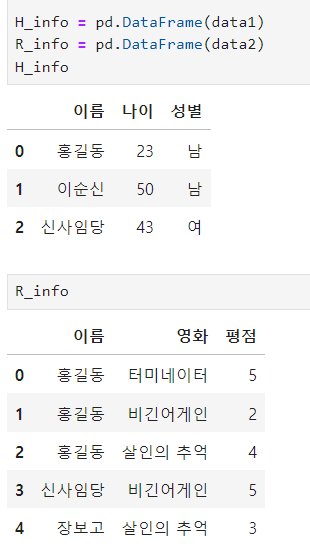
ㅡ 이름을 기준으로 inner 조인 해주기
merge ()
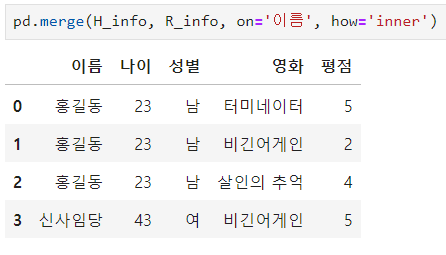
ㅡ left 조인

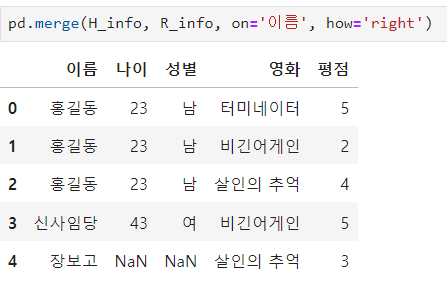
ㅡ right 조인
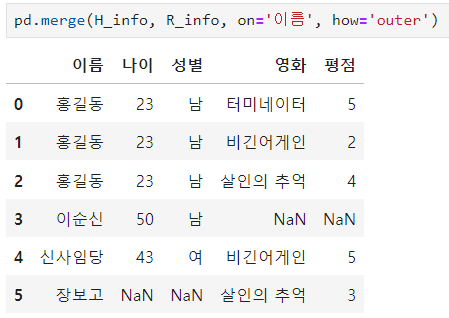
ㅡ full Outer 조인
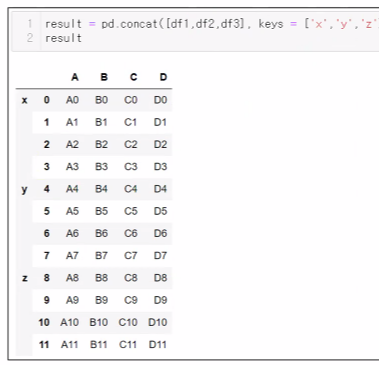
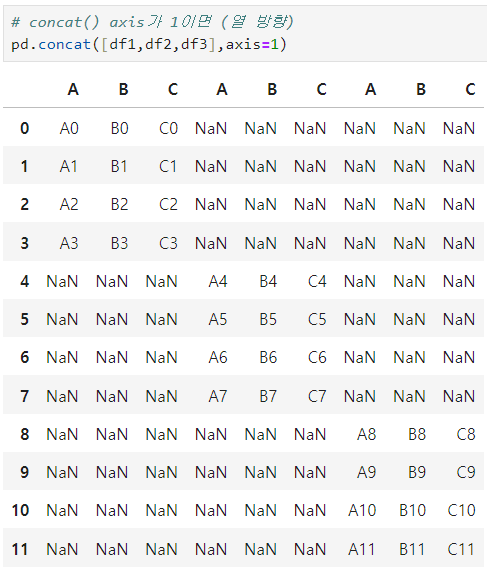
ㅡ Concat ()
축 ( axis ) 을 기준으로 병합
pd.concat ( [df1, df2], on = 중복컬럼명, how = 조인방식 )
inner : 중복값이 있는 행만 출력 ( 교집합방식 )
full Outer : 존재하는 값 모두 출력
key 속성 부여 시 다중 index 가 됨
ignore_index = True
기존 인덱스를 무시하고 새로운 인덱스 부여
[ 실습 ]




Bye
'Python' 카테고리의 다른 글
| DAY 10 ( Python library, matplotlib, 데이터 시각화, plt 실습 ) (0) | 2024.06.27 |
|---|---|
| DAY 9 ( Pandas 최종 실습 [ 범죄 현황 데이터 ], matplotlib, 데이터 시각화 기초 ) (0) | 2024.06.26 |
| DAY 7 ( 라이브러리, Numpy, Boolean indexing, Pandas ) (0) | 2024.06.24 |
| DAY 6 ( Numpy 배열 생성, 연산, Boolean indexing, Universally function ) (0) | 2024.06.21 |
| DAY 5 ( 함수 선언, 독스트링, 가변 매개변수, file 파일, numpy ) (0) | 2024.06.20 |