오늘의 노래 추천 ☃️
- 아티스트
- 효연 (HYO), 키 (KEY), 첸 (CHEN), 쟈니 (JOHNNY), 닝닝 (NINGNING), GINJO, Raiden, IMLAY, Mar Vista
- 앨범
- 2022 Winter SMTOWN : SMCU PALACE
- 발매일
- 1970.01.01
솔...직히 좋음
🔒 근데 어쩌다 이런 조합을 기획했지
DAY 9
[ category ]

ㅡ 카테고리 만들기
pd.cut ()
카테고리에 들어갈 데이터
카테고리를 분류할 기준이 되는 범주
카테고리 명칭
ㅡ> 리스트 형태의 값으로 작성
ㅡ 카테고리만 보고 싶을 때
.categories

ㅡ 카테고리만 보고 싶을 때
.categories

ㅡ 카테고리만 보고 싶을 때
.categories

ㅡ 카테고리만 보고 싶을 때
.categories

[ DataFrame 병합 ]
ㅡ Merge ()
특정 컬럼을 기준으로 병합
pd.merge ( df1, df2, on = 중복컬럼명, how = 조인방식 )
inner : 중복값이 있는 행만 출력 ( 교집합방식 )
left : 왼쪽 df 에 있는 값은 모두 출력
right : 오른쪽 df 에 있는 값은 모두 출력
full Outer : 존재하는 값 모두 출력
ㅡ 데이터 dictionary 생성

ㅡ DataFrame 에 dictionary 값 넣어주기

ㅡ 이름을 기준으로 inner 조인 해주기
merge ()
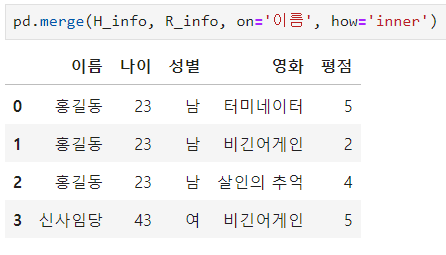
ㅡ left 조인
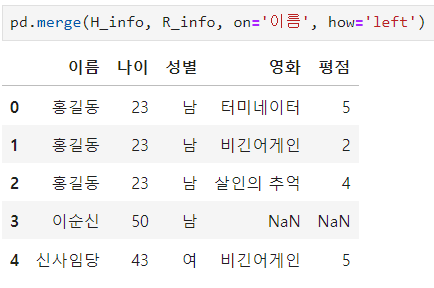
ㅡ right 조인

ㅡ full Outer 조인

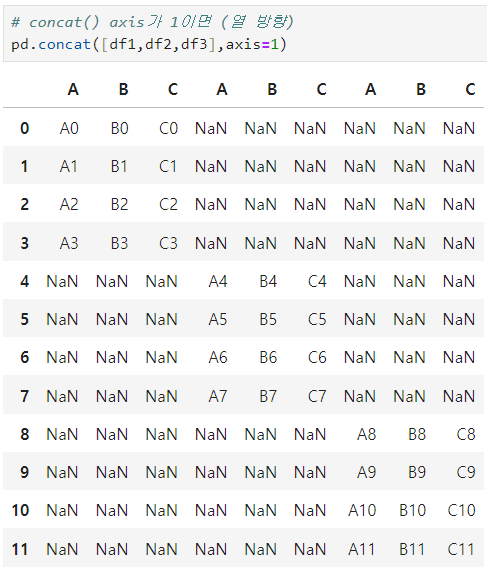
ㅡ Concat ()
축 ( axis ) 을 기준으로 병합
pd.concat ( [df1, df2], on = 중복컬럼명, how = 조인방식 )
inner : 중복값이 있는 행만 출력 ( 교집합방식 )
full Outer : 존재하는 값 모두 출력
key 속성 부여 시 다중 index 가 됨

ignore_index = True
기존 인덱스를 무시하고 새로운 인덱스 부여
[ 실습 ]



[ Pandas 최종실습 ]
범죄 현황 데이터
ㅡ Numpy, Pandas import 하기

ㅡ csv 파일 불러오기
read.csv

ㅡ Numpy, Pandas import 하기
.info ()

info 함수를 통해 결측치가 있는지 등을 파악
ㅡ 중복이 아닌 인덱스 값 조회
.index.unique ()

각 DataFrame 의 인덱스가 일치하지 않으면 비교 불가능하기 때문
ㅡ 중복이 아닌 인덱스 값 제거
.drop ()

data2021 에만 있는 인덱스 데이터인 '광주지방경찰청' 행 삭제
ㅡ 세개 데이터의 shape 이 동일해졌는지 확인
.shape ()
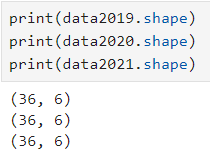
ㅡ 각 연도별로 범죄데이터의 총합을 구해 '총합계' 컬럼 생성하기
.sum ()
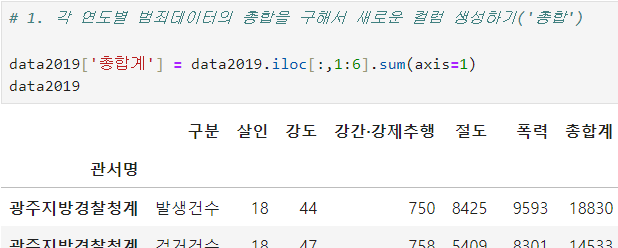
axis = 1 로 설정해야함
ㅡ 구분 컬럼의 '발생건수' 정보만 불러오기
Boolean indexing
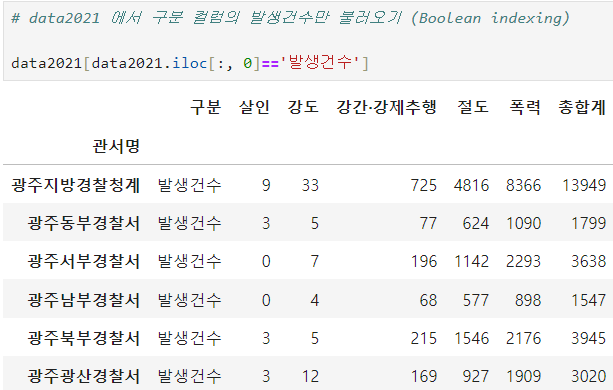
비교연산자를 이용한 Boolean indexing
* data2019 [ [ '구분' ] ] == '발생건수' 으로도 가능
ㅡ 총합 컬럼의 데이터 불러와 저장

Boolean indexing 의 결과를 변수에 넣어주기

총합계 데이터를 연도별로 변수에 저장해주기
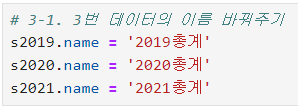
ㅡ 총합계 컬럼명을 연도별로 바꿔주기
.name
ㅡ 연도별 범죄 증감율 계산
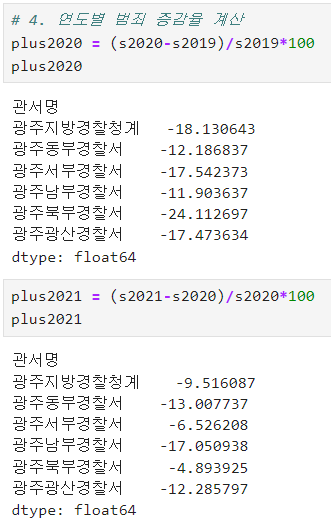
발생건수 총합 데이터를 이용해 증감율 계산
ㅡ 증감율 데이터 이름 변경
.name
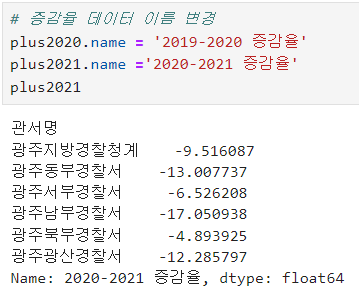
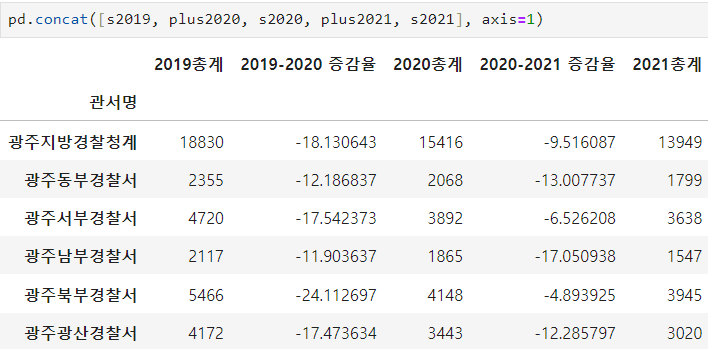
ㅡ 증감율 데이터 병합
.concat ()
.
.
.
[ end ]
[ matplotlib ]
데이터 시각화
scatter, bar, pie, histogram 등 그래프 라이브러리

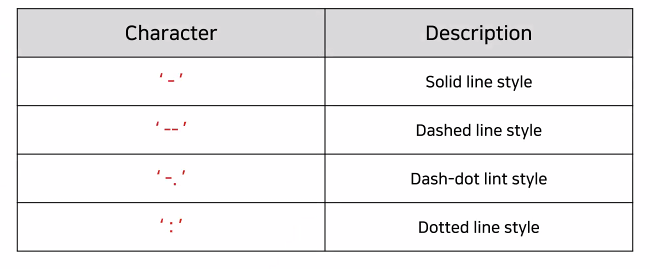
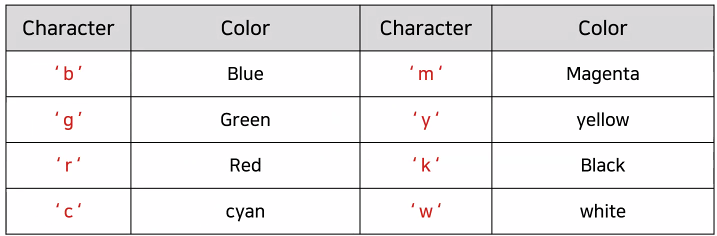
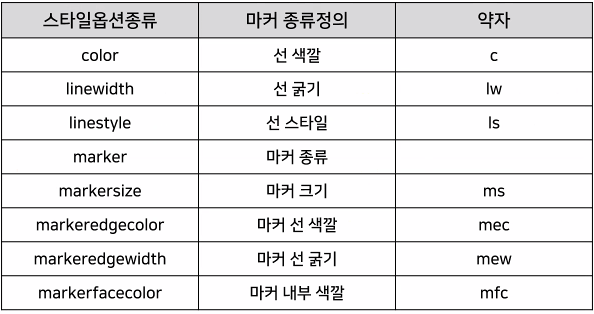
ㅡ plt.plot 스타일 옵션 ㅡ
Line plot

ㅡ pyplot import 하기 ㅡ

ㅡ Line plot 그리기 ㅡ
plt.plot ()
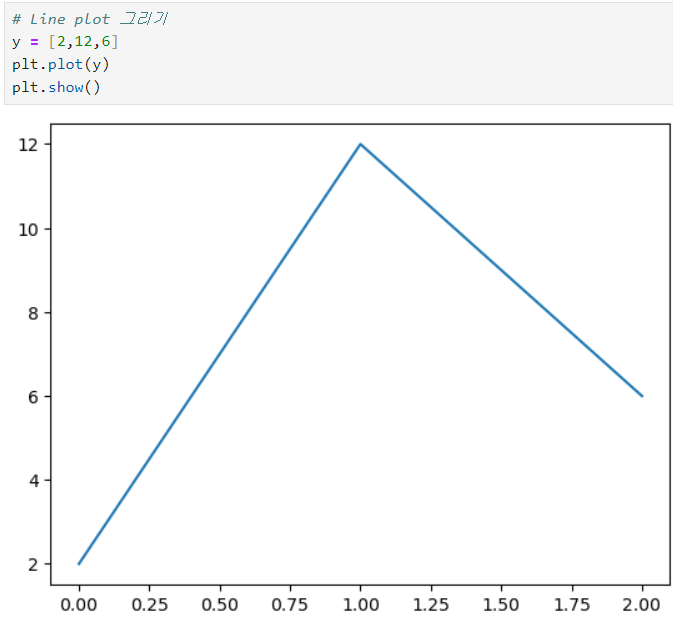
데이터를 하나만 전달하면 x 축 값은 자동으로 인덱스 부여 ( 0 부터 1씩 증가 )
* .show () => 그래프를 출력하는 기능
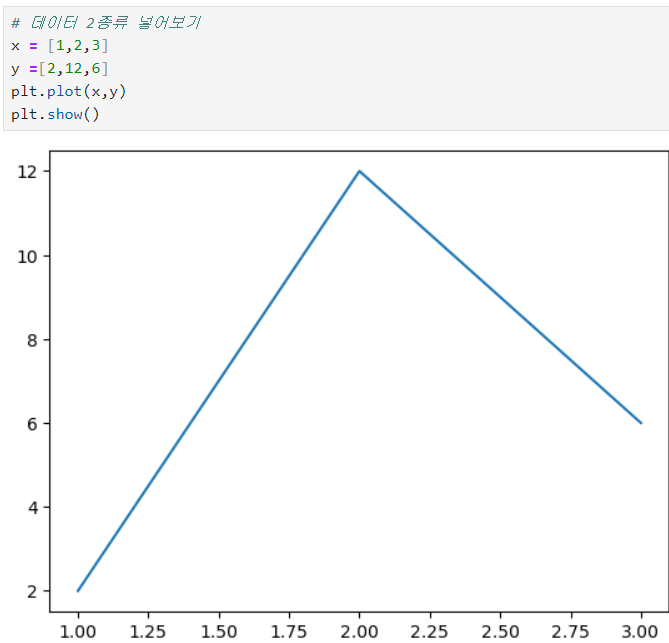
ㅡ Line plot x 축과 y 축 설정해서 그려보기 ㅡ
plt.plot ()
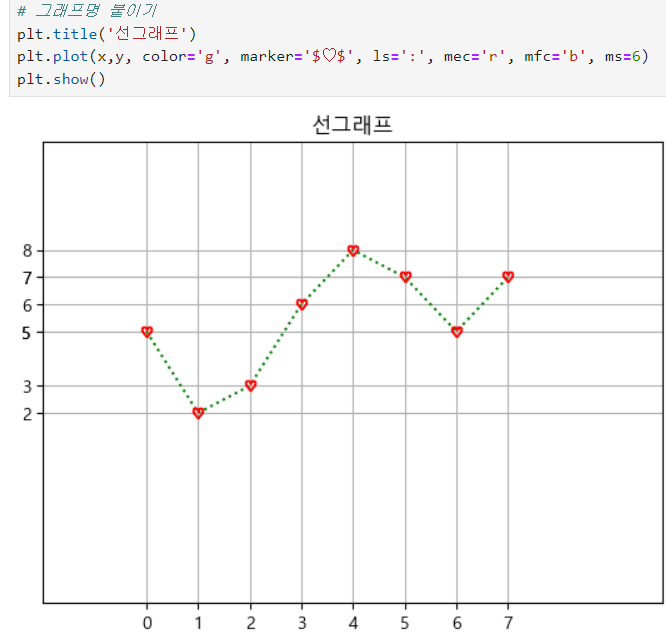
ㅡ Line plot 스타일 옵션 설정 ㅡ
character
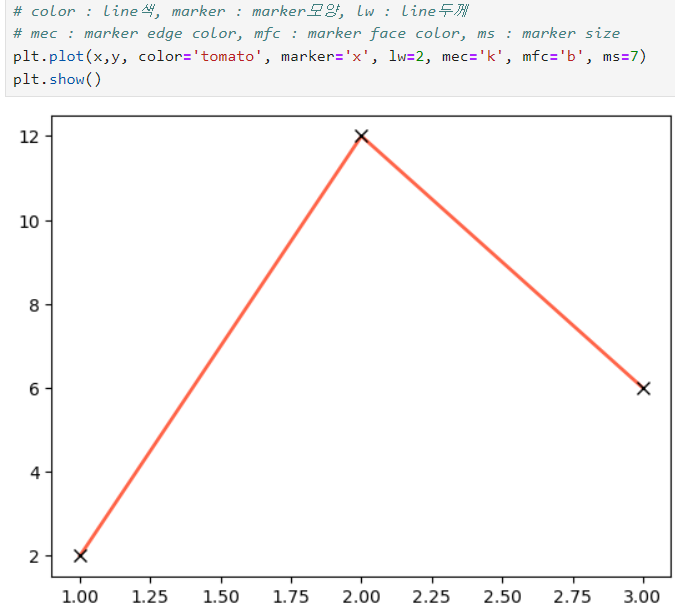
color : line색, marker : marker모양, lw : line두께
mec : marker edge color, mfc : marker face color, ms : marker size
[ 연습 문제 ]
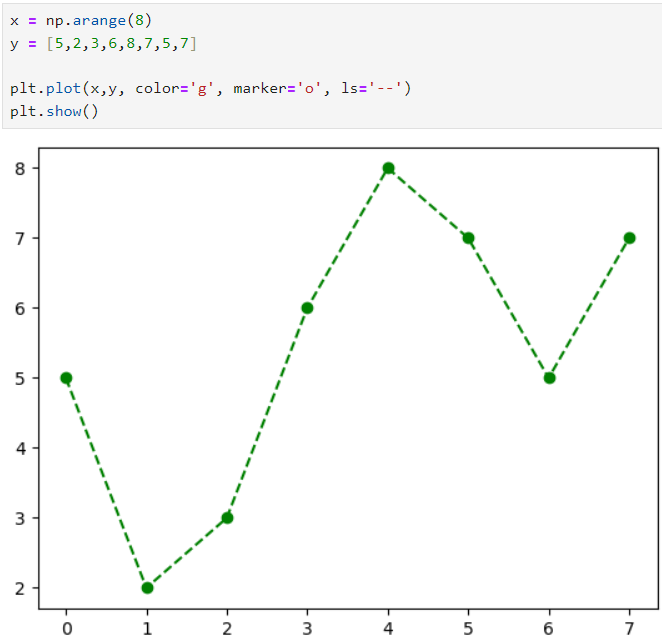
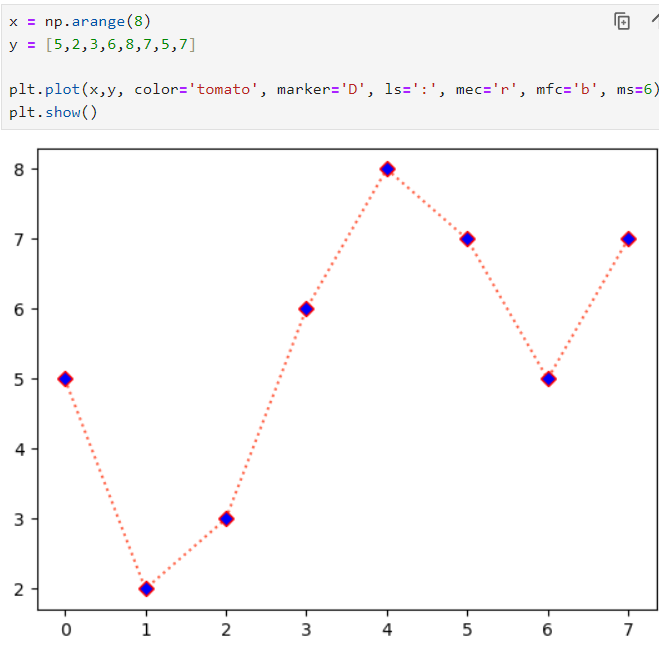
x 축 값을 arange () 함수를 이용해 범위 지정해줌
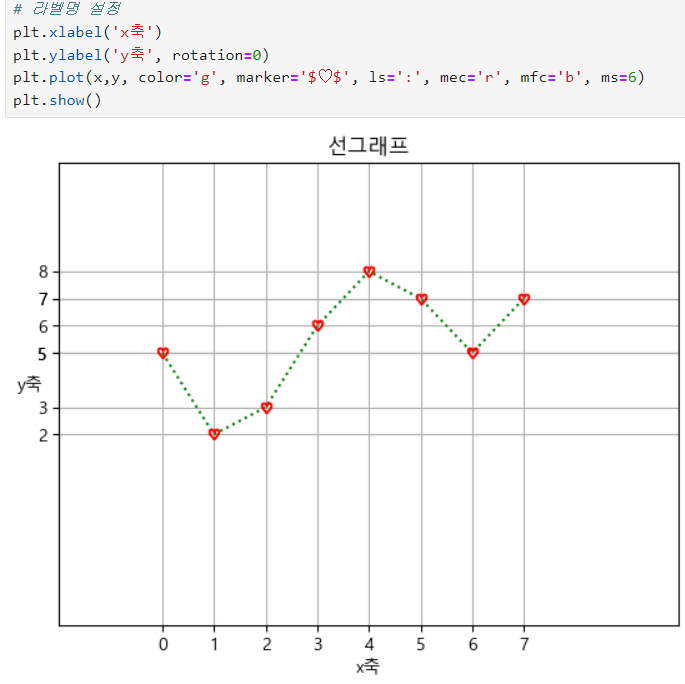
ㅡ 그 외 차트 옵션 ㅡ
xlim/ylim, grid, legend, xlabel/ylabel, title, xticks/yticks

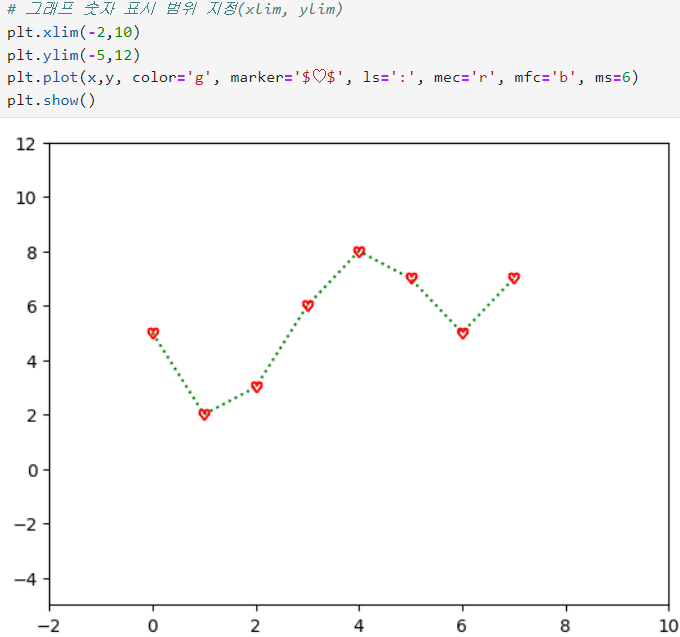

한글 폰트 사용을 위해 rc 함수를 불러와야함

Bye
'Python' 카테고리의 다른 글
| DAY 10-2 ( Python library 데이터 시각화 최종 실습 [ 복지데이터 분석 ] ) (0) | 2024.06.27 |
|---|---|
| DAY 10 ( Python library, matplotlib, 데이터 시각화, plt 실습 ) (0) | 2024.06.27 |
| DAY 8 ( Python, Pandas, pd.Series, DataFrame ) (0) | 2024.06.25 |
| DAY 7 ( 라이브러리, Numpy, Boolean indexing, Pandas ) (0) | 2024.06.24 |
| DAY 6 ( Numpy 배열 생성, 연산, Boolean indexing, Universally function ) (0) | 2024.06.21 |