오늘의 노래 추천 💄
- 아티스트
- Eminem
- 앨범
- Recovery
- 발매일
- 1970.01.01
리한나 피쳐링부분이 갑자기 생각나서요..
Just gonna stand there and watch me burn
But that's alright because I like the way it hurts
Just gonna stand there and hear me cry
But that's alright because I love the way you lie
I love the way you lie . . .
DAY 10 -2
[ 데이터 시각화 최종 실습 ]
복지 데이터 분석 및 시각화
ㅡ 라이브러리 import ㅡ

ㅡ pip install ㅡ
pip install pyreadstat

sav 파일을 읽어내기 위한 pip 설치
ㅡ sav 파일 불러오기 ㅡ
read_spss
sav 파일의 데이터는 암호화 되어있음
ㅡ 암호화된 컬럼 이름을 가시화해주기 ㅡ
.rename ()

rename 함수를 이용해 암호화된 컬럼명을 직관적으로 바꿔주기
ㅡ 필요한 컬럼만 뽑아 재대입 ㅡ
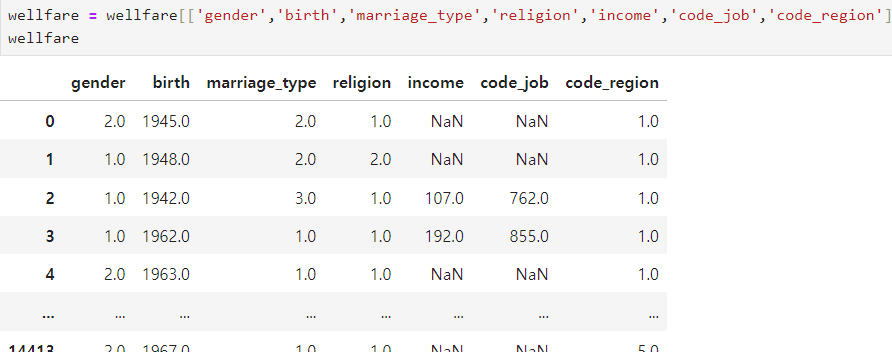
[ 성별에 따른 임금차이 ]
ㅡ gender 데이터 확인 ㅡ

ㅡ 성별 항목 rename 후 빈도 확인 ㅡ
where () , value_counts ()
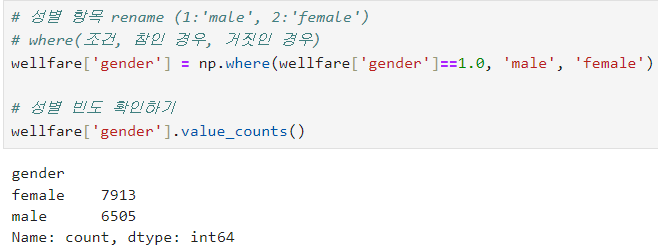
np.where ( 조건, 참일 경우, 거짓일 경우 ) 를 이용해 rename 해준결과를 재대입하고
value_counts () 로 빈도수 출력
ㅡ 성별에 따른 막대그래프 그리기 ㅡ
plt.bar ()

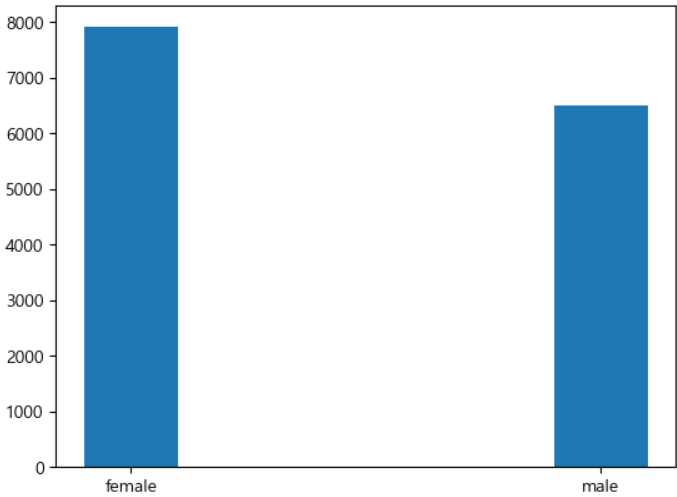

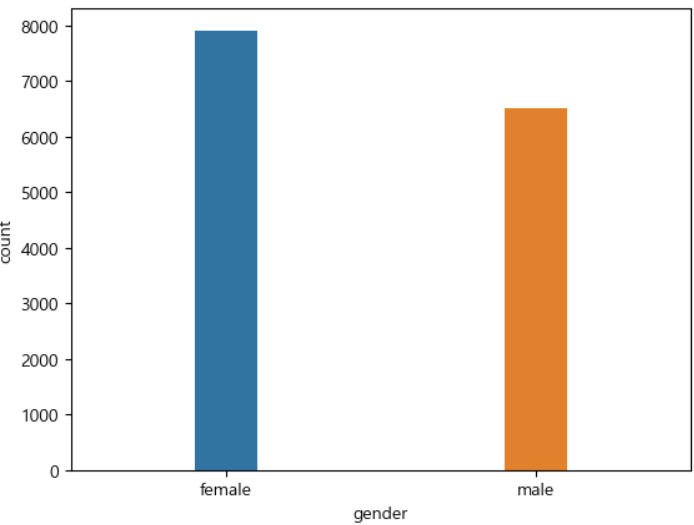
sns 를 이용한 countplot
data와 x 값을 설정해주면 자동으로 출력됨
ㅡ income 컬럼 요약통계량 확인 ㅡ
describe ()

describe 를 통해 월급 변수 값에 대한 요약통계량
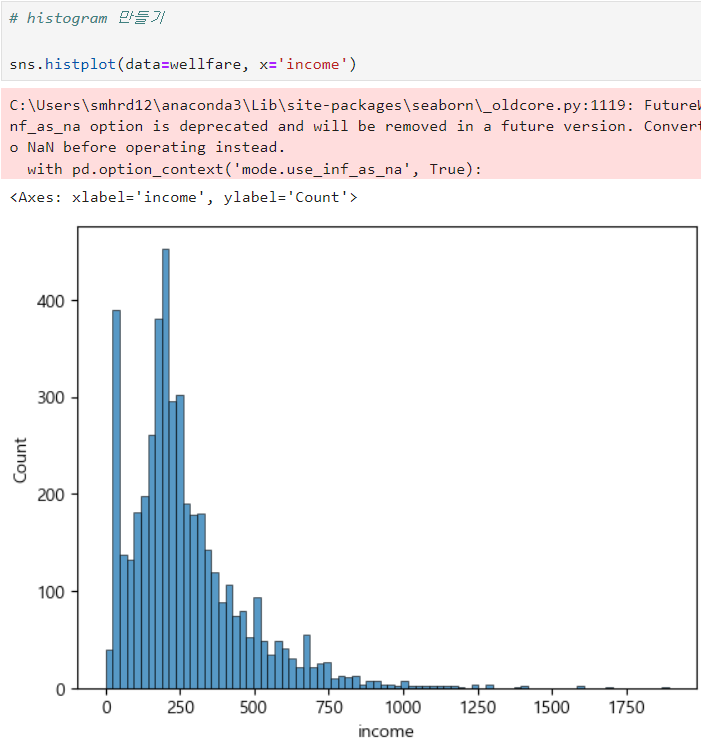
ㅡ income 컬럼 historgram ㅡ
sns.histogram ()
ㅡ 'income' 컬럼의 결측치 확인 ㅡ
isna (), sum ()

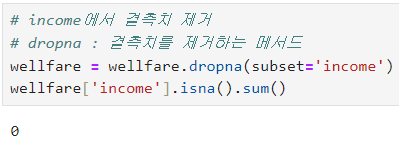
ㅡ 'income' 컬럼의 결측치 제거ㅡ
dropna ()
ㅡ 성별에 따른 월급 평균표 만들기 ㅡ
agg (), groupby ()

wellfare 를 groupby 해준 값을 agg 함수를 이용해 집계 해줌
ㅡ 데이터 시각화 ㅡ
sns.barplot


[ 나이에 따른 임금차이 ]
ㅡ income 컬럼 요약통계량 확인 ㅡ
describe ()

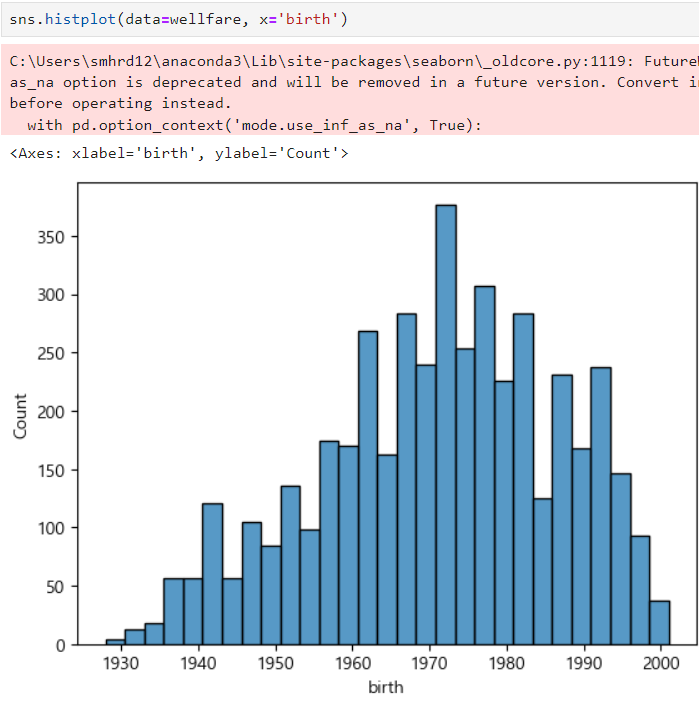
ㅡ birth 컬럼 historgram ㅡ
sns.histogram ()
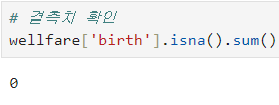
ㅡ 'income' 컬럼의 결측치 확인 ㅡ
isna (), sum ()
ㅡ age 파생변수 ( 새로운 컬럼 ) 생성ㅡ
assign ()

생년을 이용해 나이 컬럼을 새 컬럼으로 생성해주기 ㅡ> 파생변수 생성
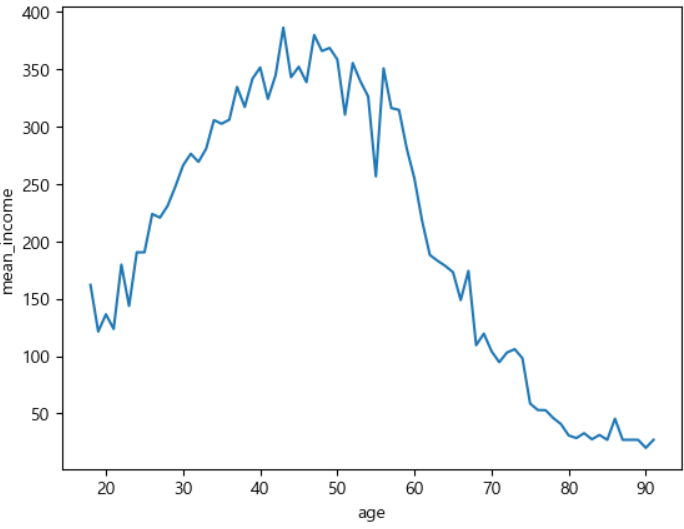
ㅡ 나이에 따른 월급 평균표 ㅡ
groupby (), agg

wellfare 를 age 를 기준으로 groupby 해준 값을 agg 함수를 이용해 집계해 평균을 구함
ㅡ 데이터 시각화 ㅡ
sns.lineplot

ㅡ 연령대 컬럼 생성 ㅡ
np.where () , value_counts ()

np.where 를 이용해 연령대별로 분류해주고 age_group 컬럼 생성
* assign 를 이용해 컬럼 생성해도 가능
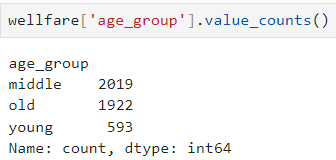
ㅡ 연령대별 빈도 구하기 ㅡ
value_counts ()
ㅡ 나이에 따른 월급 평균표 만들기 ㅡ
agg (), groupby ()
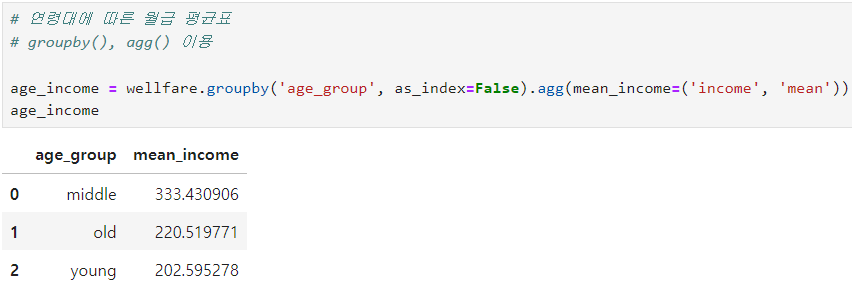
wellfare 를 age_group 를 기준으로 groupby 해준 값을 agg 함수를 이용해 집계해 평균을 구함
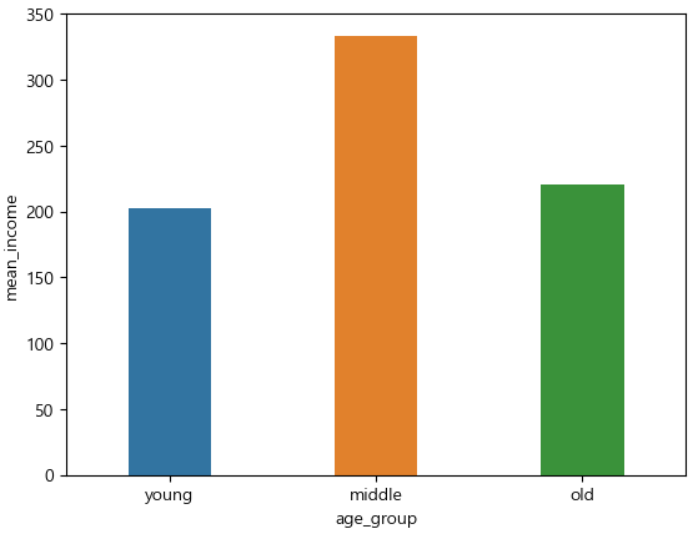
ㅡ 데이터 시각화 ㅡ
sns.barplot

ㅡ 연령대와 성별에 따른 월급 평균표 만들기 ㅡ
agg (), groupby ()
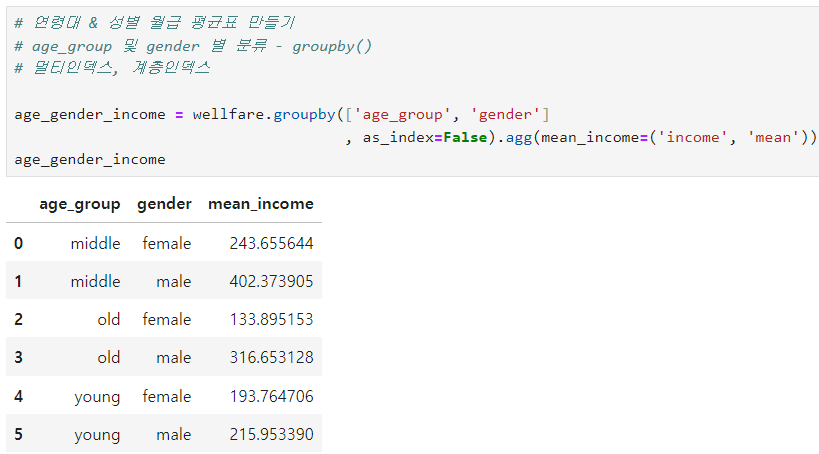
wellfare 를 age_group, gender 를 기준으로 groupby 해준 값을 agg 함수를 이용해 집계해 평균을 구함
두 개 이상 컬럼을 기준으로 분류한 멀티 인덱스 형태
ㅡ 데이터 시각화 ㅡ
sns.barplot

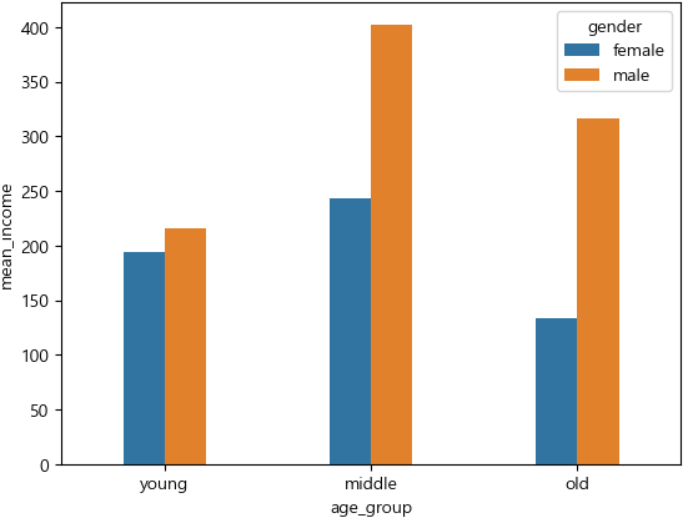
ㅡ 나이와 성별에 따른 월급 평균표 만들기 ㅡ
agg (), groupby ()

ㅡ 데이터 시각화 ㅡ
sns.lineplot

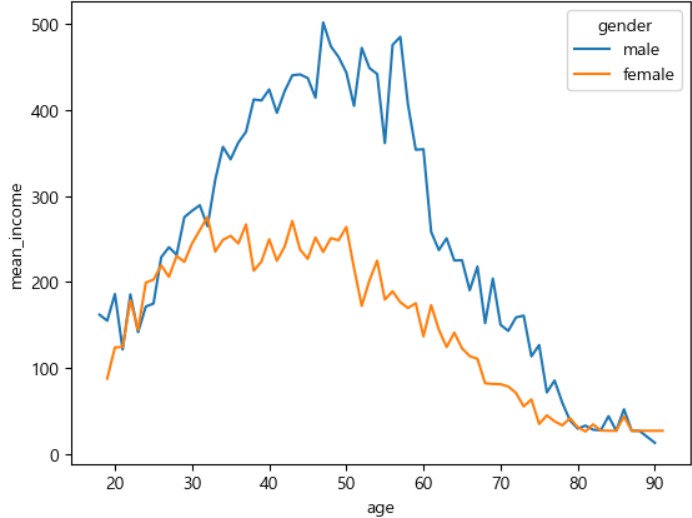
[ 직업에 따른 임금차이 ]
ㅡ 직종코드 엑셀파일 불러오기ㅡ
read_excel ()

코드화된 직업 데이터를 직종 코드북을 읽어와 DataFrame 형태로 저장해주기
ㅡ 직종코드 리스트와 wellfare df 를 병합 ㅡ
merge ()
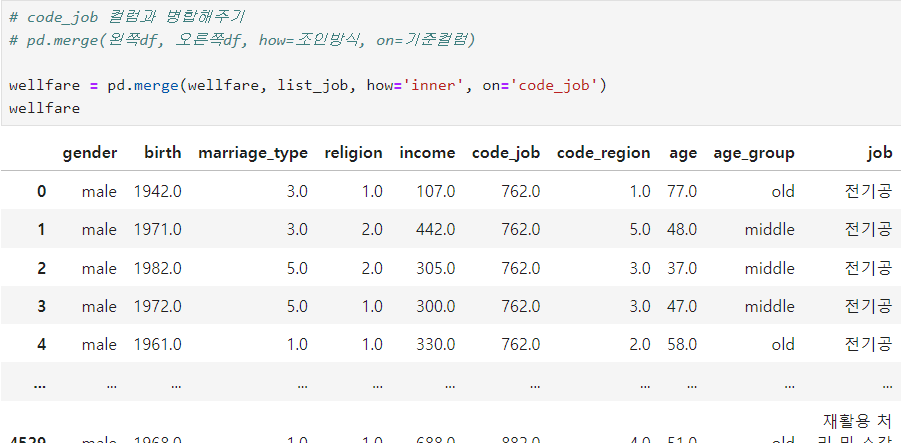
ㅡ 직종에 따른 월급 평균표 만들기 ㅡ
agg (), groupby ()
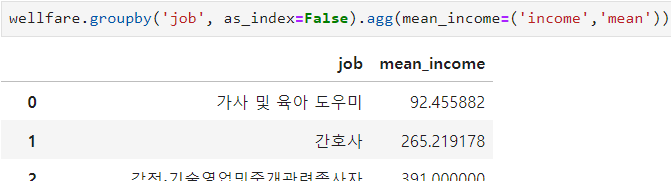
wellfare 를 job을 기준으로 groupby 해준 값을 agg 함수를 이용해 집계해 평균을 구함
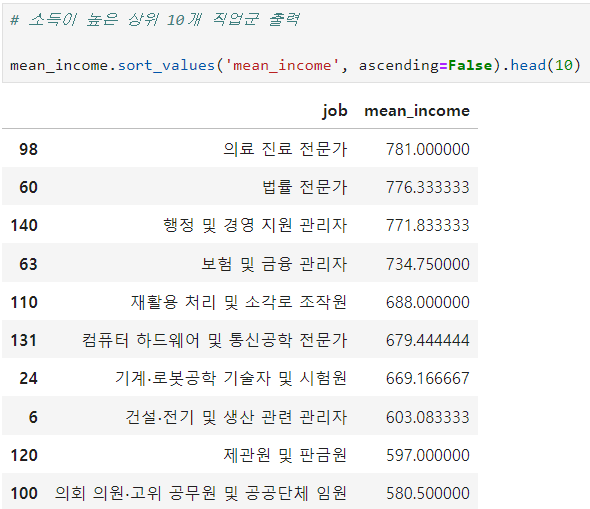
ㅡ 소득이 높은 상위 10개 직업군 출력 ㅡ
sort_values (), head ()
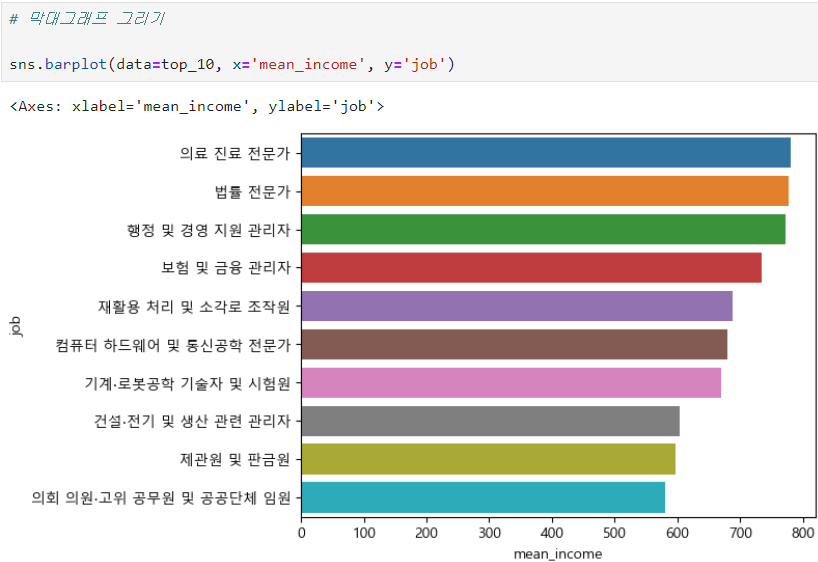
ㅡ 데이터 시각화 ㅡ
sns.barplot
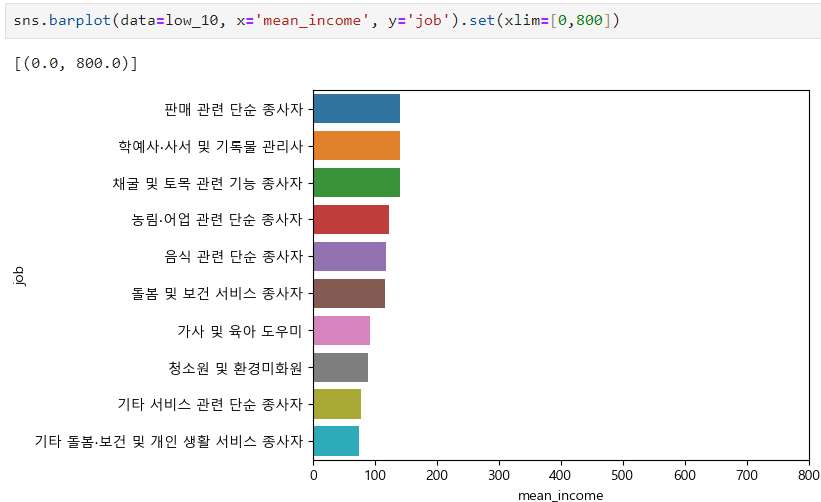

BYE
'Python' 카테고리의 다른 글
| DAY 10 ( Python library, matplotlib, 데이터 시각화, plt 실습 ) (0) | 2024.06.27 |
|---|---|
| DAY 9 ( Pandas 최종 실습 [ 범죄 현황 데이터 ], matplotlib, 데이터 시각화 기초 ) (0) | 2024.06.26 |
| DAY 8 ( Python, Pandas, pd.Series, DataFrame ) (0) | 2024.06.25 |
| DAY 7 ( 라이브러리, Numpy, Boolean indexing, Pandas ) (0) | 2024.06.24 |
| DAY 6 ( Numpy 배열 생성, 연산, Boolean indexing, Universally function ) (0) | 2024.06.21 |