오늘의 노래 추천 🐦⬛
- 아티스트
- IZ*ONE (아이즈원)
- 앨범
- BLOOM*IZ
- 발매일
- 1970.01.01
(TMI area)
고2-고3 이시기에 공부하면서 듣고 설거지하면서 듣고 걸어다니면서 듣고
외국인 멤버들 씹히는 발음까지 다 따라할 정도로 내 노동요였는데
정작 내 친구들은 앵앵거린다고 싫어함 (ㅅㅂ;) 나 혼자 들음
아이즈원 타이틀 중에 fiesta 랑 panorama 이거 두개 꼽을래
피에스타에서는 김채원 파노라마에서는 최예나가 킬링파트
저는 중딩때 프듀 48 1화부터 달린사람이라 아이즈원에 대한 감정이 좀 깊어요...
(TMI area)
DAY 6
[ 분류 모델 평가 지표 ]
train, testio
ㅡ confusion_matrix ㅡ
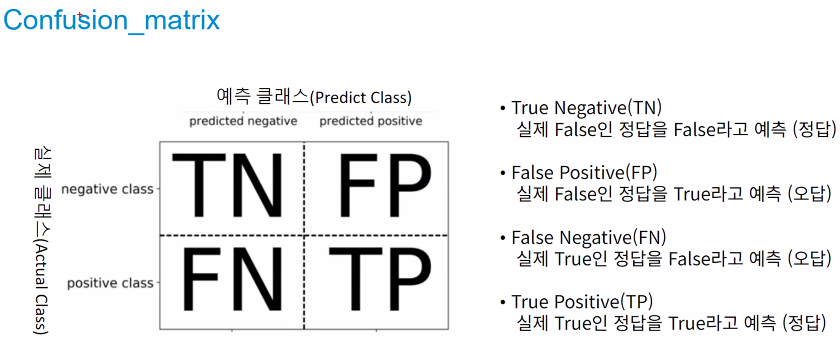
정확도
accuracy

불균형한 데이터일 경우 정확도로 성능을 평가하는 것은 문제가 될 수 있음 !
재현율
recall

실제 양성값 중 양성 예측값 비율
양성을 음성으로 잘못 판단하면 업무상 큰 영향을 주는 경우
정밀도
Precision
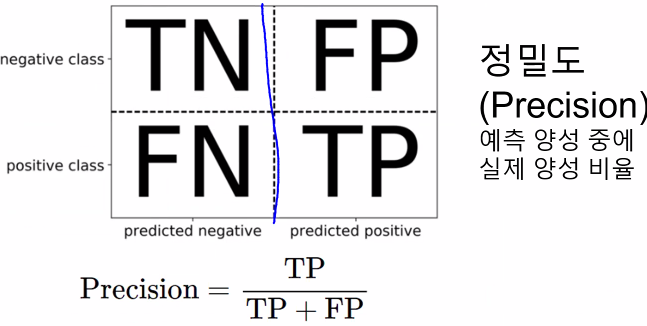
양성 예측값 중 실제 양성 비율
음성을 양성으로 잘못 판단하면 업무상 큰 영향을 주는 경우
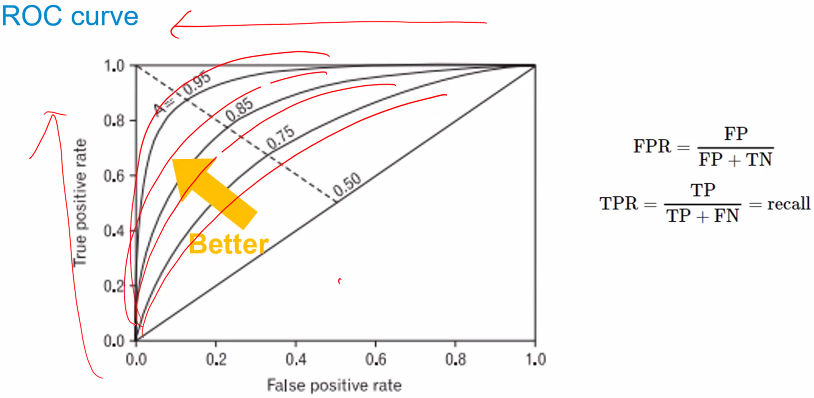
ROC curve
f1 score
recall 과 precision 의 조화평균
[ 평가지표 실습 ]
ROC curve
서로 다른 모델을 결합해 투표를 통해 최종 예측 결과를 결정
ㅡ 분류지표 import ㅡ
import

sklearn 에서 분류지표와 dataset, 필요한 기능 import
ㅡ 평가를 위한 데이터 로딩, 모델 생성 ㅡ
load, split, DecisonTree, fit, predict


평가를 위한 dataset 을 load 하고 모델 생성 후 학습시키기
ㅡ 분류 평가지표 모델 생성 ㅡ
score
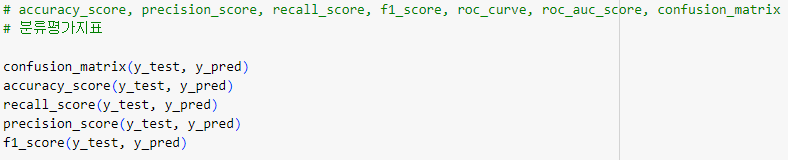
accuracy_score, precision_score, recall_score, f1_score, roc_curve, roc_auc_score, confusion_matrix
ㅡ 평가지표 결과 출력 ㅡ
precision, recall, f1 score, roc_curve


ㅡ 평가지표 결과 출력 ㅡ
predict_proba
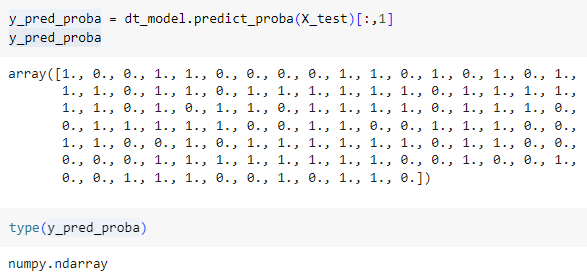
양성값만 불러오기 위해 슬라이싱 해줌
y_pred_proba 의 타입은 ndarray
ㅡ 평가지표 결과 출력 ㅡ
ROC, AUC
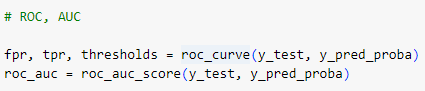
fpr, tpr, thresholds 세개의 지표를 이용해 roc_score 생성
ㅡ 평가지표 결과 출력 ㅡ
plt.plot ()


[ Data Scaling ]
데이터 스케일링
특성 ( Feature ) 과 범위 ( range ) 를 정규화하는 작업
* 특성마다 범위가 다를경우 학습하기 어려울 수 있음
학습의 안정성과 속도를 개선하지만 모델 종류나 특성에 따라 특성의 개수를 유지하는 게 좋을 수도 있음

ㅡ Standard Scaler ㅡ
변수의 평균, 표준편차를 이용해 정규분표 형태로 변환 ( 평균 0, 분산 1 )
* 이상치 ( Outlier ) 에 민감함
ㅡ Robust Scaler ㅡ
변수의 사분위수를 이용해 변환
* 이상치 ( Outlier ) 가 있는 데이터 변환 시 사용
ㅡ MinMax Scaler ㅡ
변수의 Max, Min 값을 이용해
*
ㅡ Normalizer Scaler ㅡ
ㅡ data scaling code ㅡ

sklearn.processing 에서 scaler 를 불러온 뒤 객체 생성 후 학습시키고 transform 으로 스케일 변환
[ Linear Regression Model ]
선형 회귀 모델
y = ax + b
* 기울기, 절편

x1, x2 등의 각각 특징의 기울기 ( 가중치 ) 를 구함
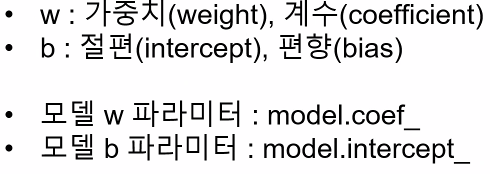
ㅡ > 평균제곱오차가 최소인 w 와 b 값을 구한다

비용함수로 수식을 검증
" 경사하강법 "
[ 성적 데이터 이용 회귀 실습 ]
여러 개의 ML model 을 연결해 더 강력한 model 을 만드는 기법
* 분류와 회귀에 모두 사용 가능
ㅡ 라이브러리 import ㅡ
impot, LinearRegression
ㅡ DataFrame 생성 ㅡ
pd.DataFrame, index, columns

[ 주택 가격 회귀 예측 실습 ]
특성변수를 이용해 주택가격 회귀예측
* 특성곱이라는 특성공학 이용
ㅡ 라이브러리 import ㅡ
impot, LinearRegression
ㅡ 데이터 정보 확인 ㅡ
info (), columns

필요없는 컬럼 ( unnamed )삭제 ( 저같은 경우는 인덱스번호로 지정했습니다 )

ㅡ 문제 답지 나누기 ㅡ
drop

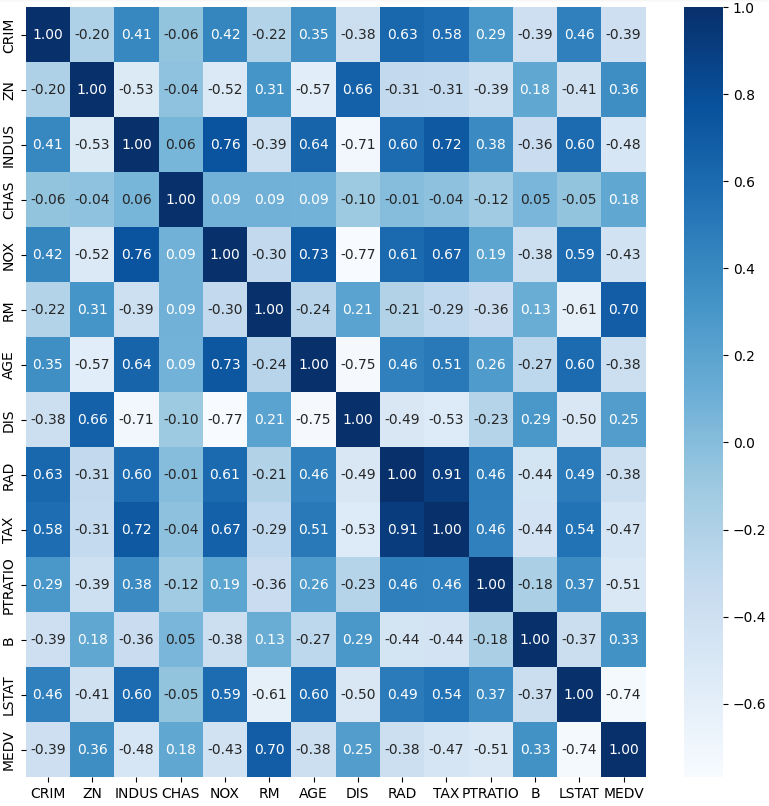
ㅡ 데이터 상관관계를 히트맵으로 작성 ㅡ
corr (), sns.heatmap ()

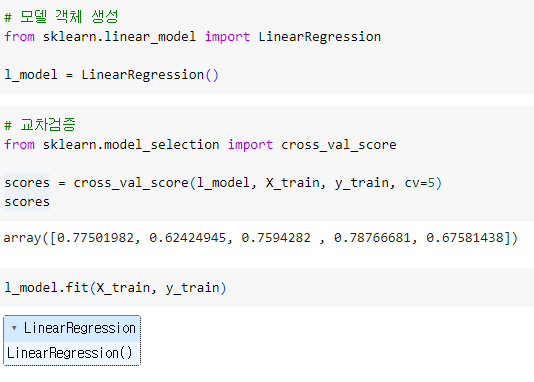
ㅡ linear regression 모델 생성 및 교차 검증, 학습 ㅡ
LinearRegression, cross_val_score, fit
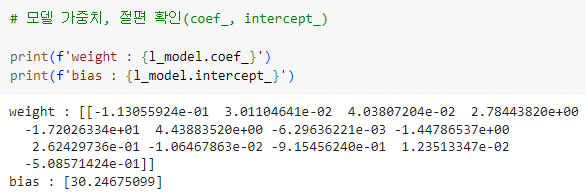
ㅡ linear regression 모델 가중치, 절편 확인 ㅡ
.coef_, .intercept_
ㅡ 특성곱 ㅡ
데이터의 특징을 늘리는 것
linear regression 은 특징이 적으면 모델이 단순해짐
ㅡ> 성능 저하
linear regression은 파라미터 조절이 안됨
ㅡ> 각 특징들의 데이터를 곱해서 새로운 특징 생성

a = b (대입연산자) : 원본데이터와 동기화 되는 '얕은 복사'
pd.DataFrame.copy () : 복사 당시의 DataFrame 상태를 복사하는 '깊은 복사'
ㅡ data copy ㅡ
copy
ㅡ 상관관계 확인 후 히트맵 작성 ㅡ
corr (), sns.heatmap ()

ㅡ 1차 함수로 특성 확장 전 예측 모델 만들기 ( LSTAT 특성 이용 ) ㅡ
LinearRegression, fit, predict, plt.scatter

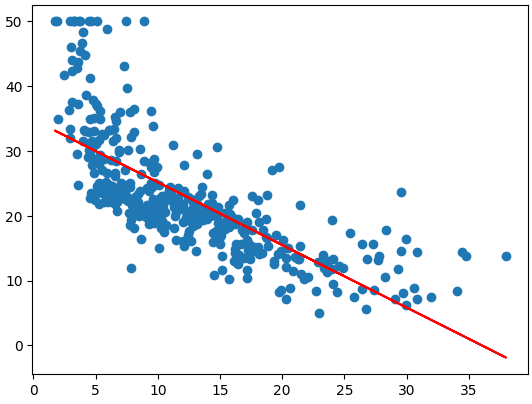
특성 확장 전 1차 함수 형태로 LSTAT 특성을 활용해 모델을 학습시키고 예측 값 그래프 그리기
ㅡ 특성 제곱을 통해 특성 확장 ㅡ
**, LinearRegression, fit, predict, plt.scatter

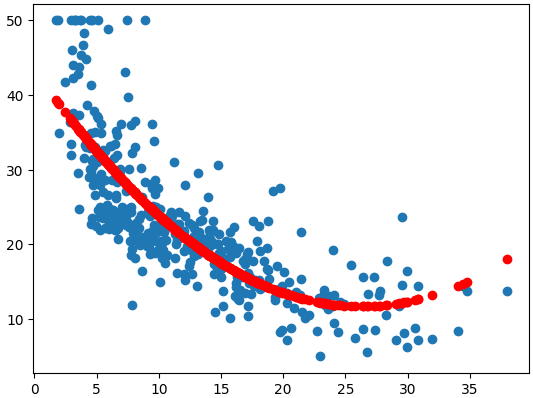
LSTAT 특성을 제곱한 새로운 컬럼을 추가 해준 train 데이터를 학습하고 예측
ㅡ> 좀 더 맞춤화된 모습을 확인 가능
ㅡ X_test 데이터로 예측 후 평가 ㅡ
corr (), sns.heatmap ()

학습한 적 없는 X_test 데이터로 ( 특성곱 추가 후 ) 예측해보고 평가
ㅡ 1차 함수로 특성 확장 전 예측 모델 만들기 ( RM 특성 이용 )ㅡ
LinearRegression, fit, predict, plt.scatter

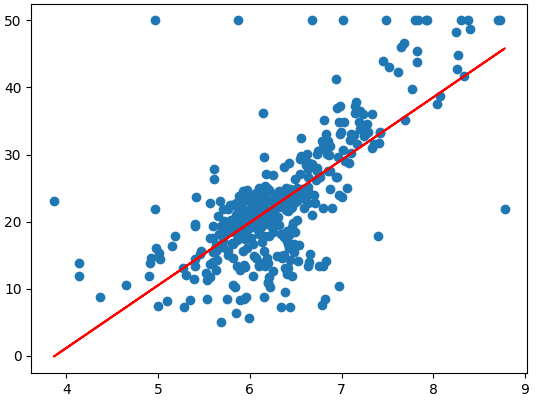
특성 확장 전 1차 함수 형태로 RM 특성을 활용해 모델을 학습시키고 예측 값 그래프 그리기
ㅡ 특성 제곱을 통해 특성 확장 ㅡ
**, LinearRegression, fit, predict, plt.scatter


RM 특성을 제곱한 새로운 컬럼을 추가 해준 train 데이터를 학습하고 예측
ㅡ> 좀 더 맞춤화된 모습을 확인 가능
ㅡ X_test 데이터로 예측 후 평가 ㅡ
corr (), sns.heatmap ()

학습한 적 없는 X_test 데이터로 ( 특성곱 추가 후 ) 예측해보고 평가
ㅡ 전체 특성곱 밑단계 ㅡ
drop, copy
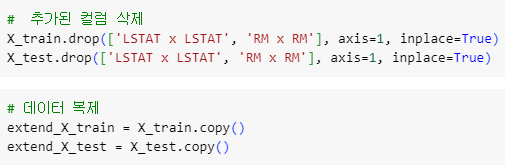
추가했던 특성곱 컬럼을 제거하고 전체 특성곱을 진행할 DataFrame 을 copy
ㅡ 특성곱을 통한 특성 확장 ( 모든 컬럼 이용 ) ㅡ
for
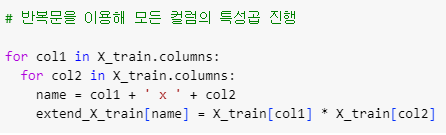
for 반복문을 통해 전체 컬럼의 특성곱 진행
X_test 도 똑같이 진행
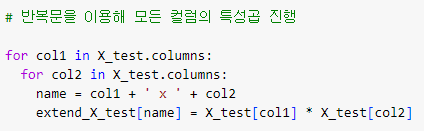
ㅡ 특성곱 모델 생성 및 평가 ㅡ
LinearRegression
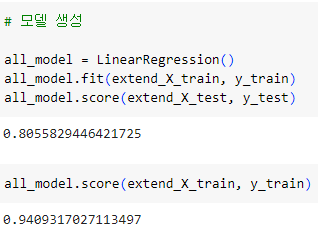
train, test 데이터 예측 평가가 상이한 것으로 보아 과대적합이 일어난 것으로 추정할 수 있음
ㅡ> 이런 overfit 를 규체해주는 모델 사용
ㅡ Linear Model 정규화 ㅡ
Reguralization ( Lasso, Ridge )

모형이 과도하게 최적화 되었을 때 제약조건을 통해
ㅡ> 선형회귀 계수(w) 의 값에 제약을 주어 overfit 방지

Lasso : 모든 원소를 똑같은 힘으로 규제해 특정 계수들은 0이됨
* 특정선택 ( Feature Selection ) 이 자동으로 이뤄짐
** alpha 으로 규제의 광도 설정
Ridge : 모든 원소를 골고루 규체를 적용해 0에 가깝게 수렴하도록 만듬
ElasticNet : L1, L2 모델을 적절히 혼합해 사용
ㅡ Lasso, Ridge 적용 ㅡ
Lasso, Ridge
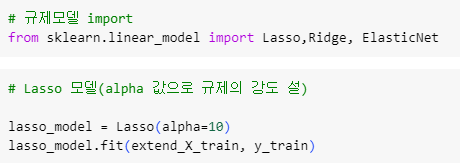
linear_model 에서 Lasso, Ridge, ElasticNet 을 import 하고 Lasso 는 alpha 값을 조정
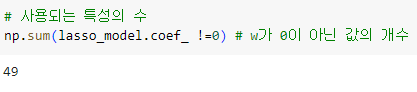
ㅡ Lasso 모델 학습 후 weight 값 확인 ㅡ
coef_

ㅡ Lasso 모델 train, test 의 score 값 비교 ㅡ
score
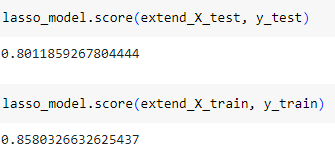
규제값 ( alpha ) 을 늘려가면서 조절

BYE