오늘의 노래 추천 🦁
- 아티스트
- Red Velvet (레드벨벳)
- 앨범
- The Red Summer - Summer Mini Album
- 발매일
- 1970.01.01
정말 동물원 or safari 느낌이 나는 첫 귀에도 듣기 좋은 곡
DAY 4
[ Ensemble model ]
앙상블
여러 개의 ML model 을 연결해 더 강력한 model 을 만드는 기법
* 분류와 회귀에 모두 사용 가능
3가지 Ensemble 기법 ㅡ> " Voting, Bagging, Boosting "
[ Voting ]
Ensemble Voting 방식
서로 다른 모델을 결합해 투표를 통해 최종 예측 결과를 결정

Hard Voting VS Soft Voting
voting의 종류

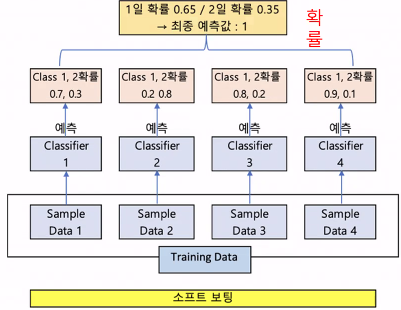
ㅡ> 더 학습률이 높고 최적화됨
[ Bagging ]
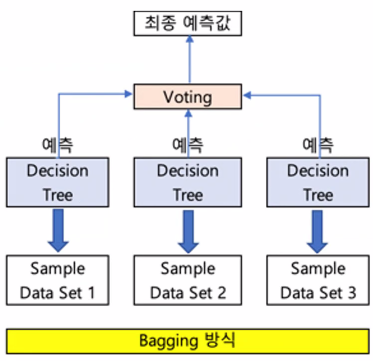
Ensemble Bagging 방식
'같은 알고리즘' 으로 여러개의 모델을 만들어 투표를 통해 최종 예측 결과를 결정
ex ) random forest
[ Boosting ]
Ensemble Boosting 방식
성능이 낮은 여러 모델 이용
1. 첫 모델이 예측하면 결과에 따라 오차 데이터에 '가중치' 부여
2. 가중치가 다음 모델에 영향을 주고 오차 데이터에 집중해
ㅡ> 개선된 분류 규칙을 만드는 것 반복, 성능 향상된 모델을 만듬
ex ) AdaBoost, GradientBoost, XGBoost
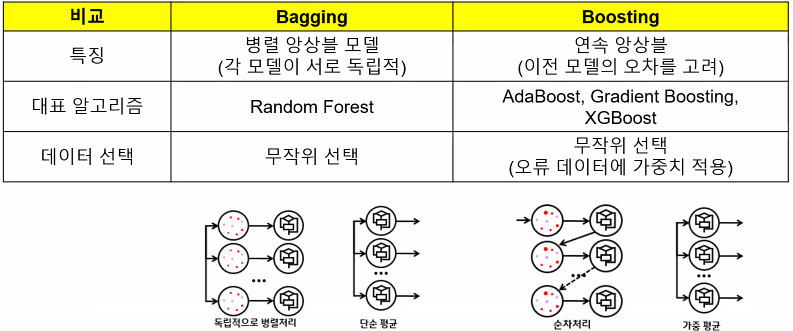
voting과 Bagging은 병렬 구조로 독립적인 반면
Boosting은 이전 모델의 오차를 고려해 순차 처리하는 연속 앙상블임
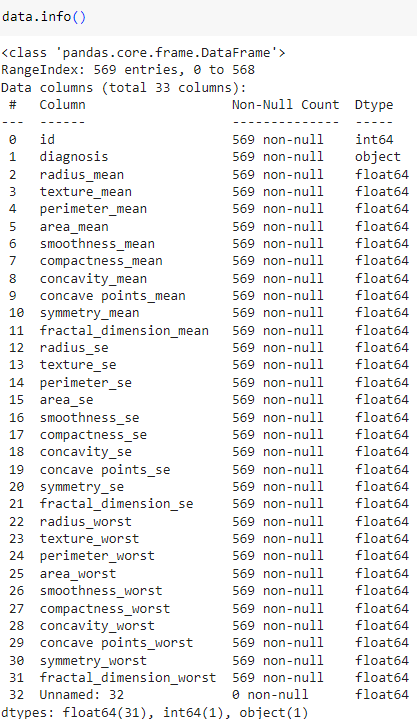
[ RandomForest 유방암 데이터 실습 ]
유방암 데이터를 이용해 100개의 트리로 구성된 RandomForest 모델로 학습,
특징 중요도를 구하고 bar 차트로 표현
ㅡ RandomForest ㅡ
여러 개의 결정 트리 분류 모델이 각자의 데이터를 샘플링 해 개별적으로 학습
ㅡ> 모든 분류기가 soft voting 을 통해 예측 수행
서로 다른 방향의 과대적합 모델들을 만들어 평균을 내고 일반화
* 분류와 회귀 모두 사용 가능

RandomForestClassifier ( n_estimators, random_state )
* random_state = 100 으로 설정
ㅡ 드라이브 마운팅 후 data 불러오기 ㅡ
pd.read_csv
ㅡ 불필요한 column 삭제 ㅡ
drop ( axis=1 )

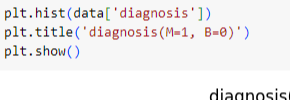
ㅡ 답지 데이터 mapping ㅡ
map ()

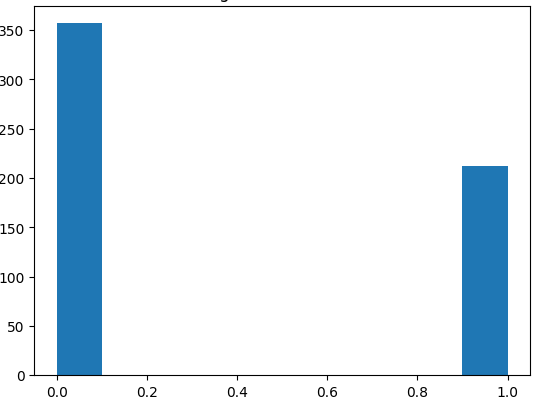
ㅡ 답지 데이터 시각화 ㅡ
plt.hist ()
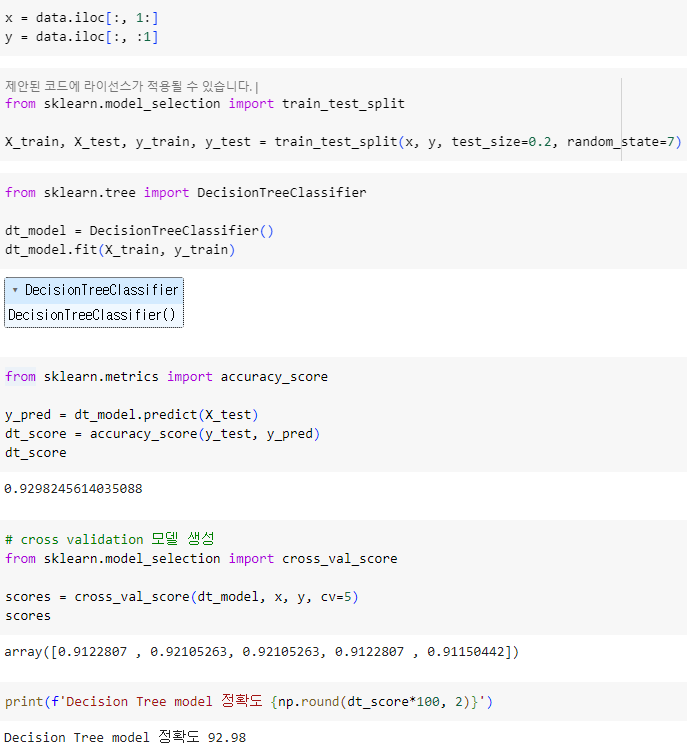
ㅡ Decision Tree model 생성 ㅡ
DecisionTreeClassifier
ㅡ knn, LR, voting 모델 import ㅡ
VotingClassifier, KNeighborsClassifier, LogisticRegression

VotingClassifier 은 분류/회귀에서 분류 모델 사용
ㅡ knn, lr 개별 모델 생성 ㅡ
KNeighborsClassifier, LogisticRegression

max_iter ㅡ> 학습 과정에서 사용할 최대 반복 횟수 ( 기본 100 )
각각 n_neighbors, max_iter 값 설정
ㅡ Voting 앙상블 모델 생성 ㅡ
VotingClassifier

estimators : 사용할 개별 모델들을 리스트 형식으로 정의
Voting 방식은 soft 로 지정
ㅡ 앙상블/개별 모델 학습, 예측 ㅡ
fit (), predict ()


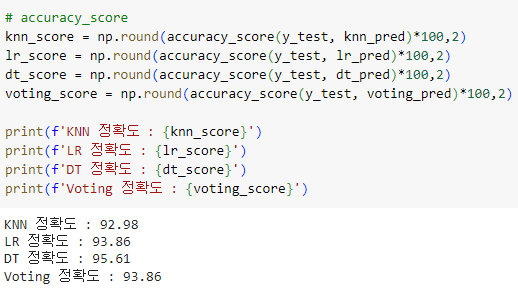
ㅡ 각 모델 별 score 출력 ㅡ
accuracy_score ()
ㅡ RandomForest parameter ㅡ

n_estimators : tree 개수 ( 기본 100 )
max_features : DT 최종 결과 개수
그 외 max_depth, min_samples_split, min_samples_leaf 등
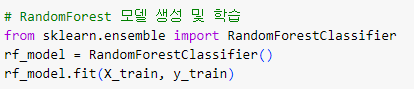
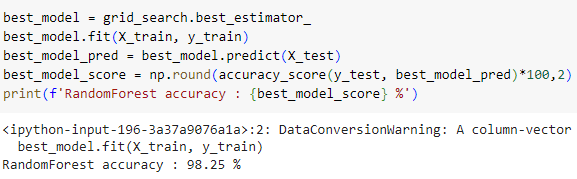
ㅡ RandomForest 모델 생성 및 학습 ㅡ
RandomForestClassifier
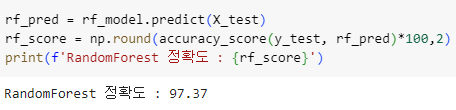
ㅡ RandomForest 정확도 출력 ㅡ
accuracy_score ()
GridSearchCV
ㅡ RandomForest hyper parameter tuning ㅡ
파라미터 튜닝

ㅡ params 파라미터 설정 ㅡ
GridSearCV, params
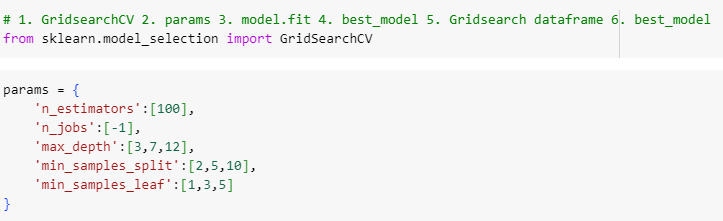
n_estimators 기본값 100, n_jobs=-1 모든 cpu 코어를 통해 학습
ㅡ 모델 생성, 학습, 평가 ㅡ
GridSearCV, fit
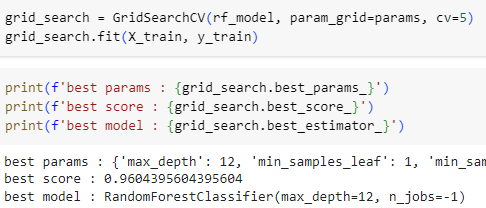
ㅡ 결과 출력 ㅡ
cv_results_
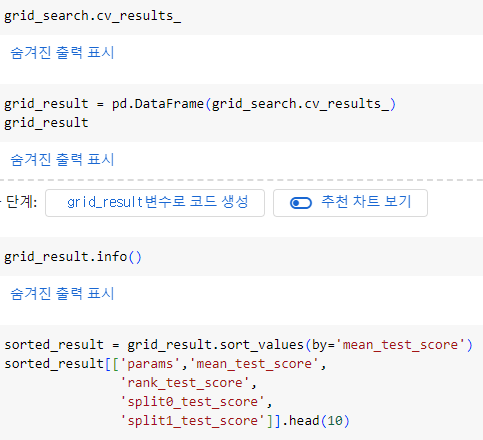
cv_results_를 DataFrame 형태로 저장하고 정보를 정렬해 필요한 값 출력
[ Adaboost 유방암 데이터 실습 ]
유방암 데이터를 이용해 100개의 트리로 구성된 Adaboost 모델로 학습,
특징 중요도를 구하고 bar 차트로 표현
ㅡ AdaBoost ㅡ
Decision Tree 기반 모델로 각 트리들이 독립적으로 존재함
ㅡ> 제 해결
들어 평일반화
* 분류와 회귀 모두 사용 가능
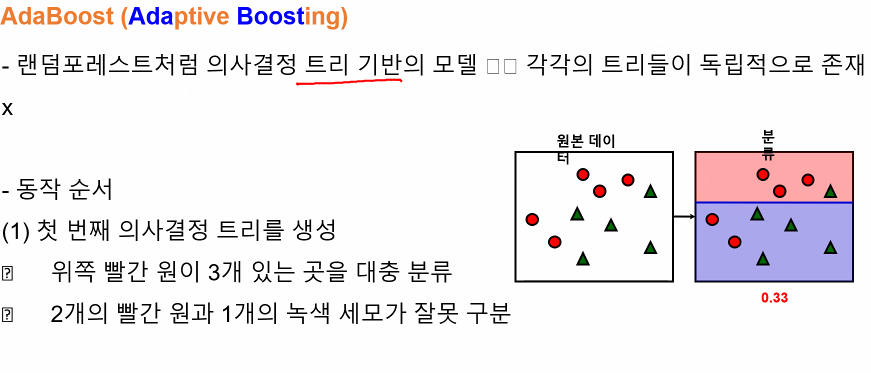
Decision Tree 기반의 모델 ㅡ> 각 트리들이 독립적으로 존재

ㅡ AdaBoosting ㅡ
Ensemble Boosting

ㅡ library import, AdaBoost model 생성 ㅡ
AdaBoostClassifier
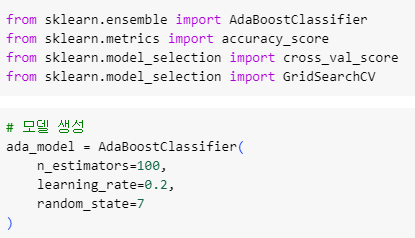
learning_rate ( 학습률 ) 은 보통 0.1, 0.2 n_estimators 는 기본값 50
ㅡ Cross Validadtion 교차 검증 ㅡ
cross_val_score

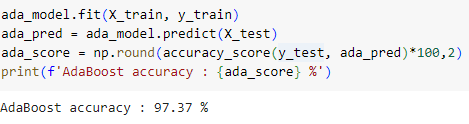
ㅡ 모델 학습, 예측, 평가 ㅡ
fit, predict, accuracy_score
ㅡ AdaBoost 특성 중요도 출력 ㅡ
feature_importances_
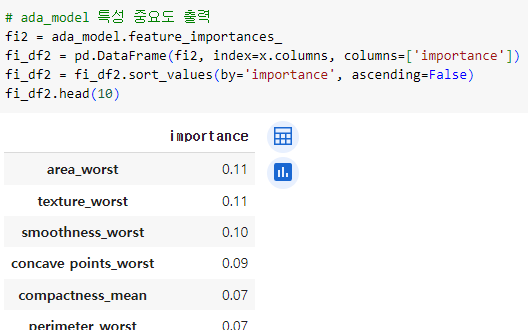

feature_importances_ 를 이용해 특성 중요도를 구하고 DataFrame 형태로 변환 후 정렬해 출력
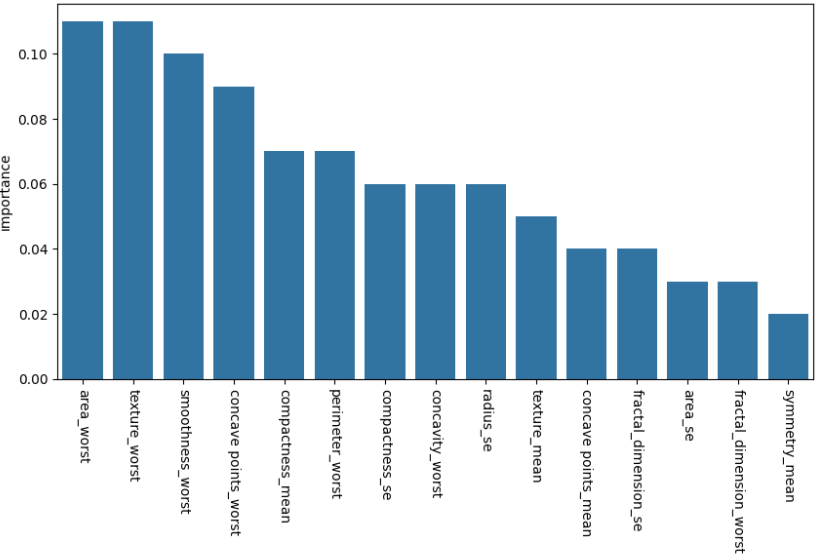
[ GBM 유방암 데이터 실습 ]
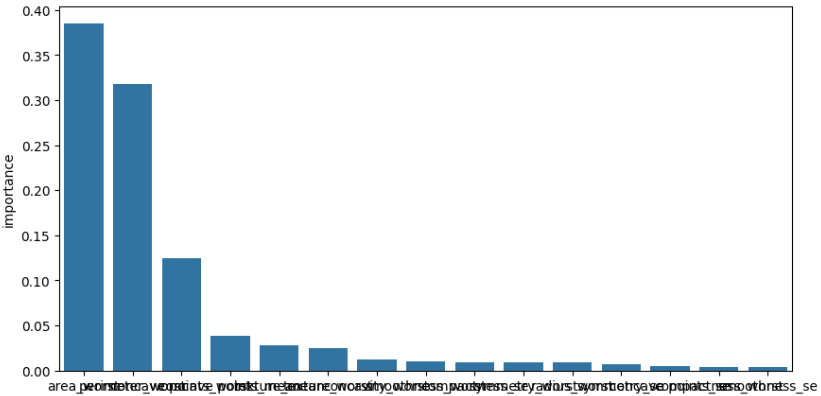
유방암 데이터를 이용해 100개의 트리로 구성된 GBM 모델로 학습,
특징 중요도를 구하고 bar 차트로 표현
ㅡ GBM ㅡ
여러개의 Decision Tree 를 묶어 강력한 모델을 만드는 Ensemble 기법
ㅡ> AdaBoost 와 유사하지만 AdaBoost 와 달리 강력한 사전 가지치기 사용
RandomForest 보다 성능이 뛰어난 경우가 많지만,
학습시간이 오래걸리고 parameter tuning 에 많은 노력 필요
* 분류와 회귀 모두 사용 가능

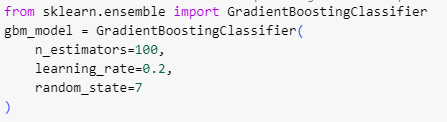
library import 이후 GBM 분류 모델 생성 함수를 호출해 객체를 생성하고
소괄호에 매개변수와 hyper parameter를 설정

n_estimators 트리 model의 개수, learning_rate 학습률 ( 가중치 갱신의 변동폭 조정 )
ㅡ GBM ㅡ
Ensemble Boosting

ㅡ GBM 모델 import 후 생성 ㅡ
GradientBoostingClassifier
ㅡ Cross Validation 교차 검증 ㅡ
cross_val_score ()

ㅡ 모델 학습, 예측, 평가 ㅡ
fit, predict, accuracy_score

ㅡ GBM 특성 중요도 출력 ㅡ
feature_importances_

feature_importances_ 를 이용해 특성 중요도를 구하고 DataFrame 형태로 변환 후 정렬해 출력
[ XGBoost 유방암 데이터 실습 ]
유방암 데이터를 이용해 100개의 트리로 구성된 XGBoost모델로 학습,
특징 중요도를 구하고 bar 차트로 표현
ㅡ XGBoost ㅡ
가장 각광받는 앙상블 모델 알고리즘 중 하나
GBM 을 기반으로 하지만 GBM 에서 제공하지 않는
"Early Stopping" 기능과 과대적합 방지를 위한 규제가 포함
ㅡ> GBM 의 단점인 느린 학습 시간과 과대적합 문제 해결
서로 다른 방향의 과대적합 모델들을 만들어 평균을 내고 일반화
* 분류와 회귀 모두 사용 가능
** sklearn 에서 제공하지 않음
ㅡ XGBoost ㅡ
Ensemble Boosting

ㅡ XGBoost 모델 import 후 생성 ㅡ
XGBClassifier
sklearn 에서 제공하지 않기 때문에
!pip install xgboost 를 이용해 설치 필요

ㅡ Cross Validation 교차 검증 ㅡ
cross_val_score ()

ㅡ 모델 학습, 예측, 평가 ㅡ
fit, predict, accuracy_score

[ XGBoost Early Stopping 조기중단 ]
유방암 데이터를 이용해 100개의 트리로 구성된 XGBoost모델로 학습,
특징 중요도를 구하고 bar 차트로 표현
ㅡ XGBoost early Stoppingㅡ
Ensemble Boosting

train 데이터를 split 해서 validation data 생성
ex) X_train ㅡ> X_tra, X_val
ㅡ train 데이터 split ㅡ
train_test_split


train 데이터를 split 해서 validation 데이터를 만듬
ㅡ xgb 모델 생성 ㅡ
XGBClassifier

ㅡ 평가를 수행할 data set 만들기 ㅡ
eval_set

[ ( train 문제, train 답지 ), ( val 문제, val 답지 ) ]
ㅡ early stopping 모델 학습 ㅡ
fit, parameter


조기 종료 parameter ㅡ> early_stopping_rounds, early_metric, early_set
분류 모델의 평가 지표 ㅡ> logloss, error, auc, aucpr

fit ( x, y, 데이터 셋, early stopping parameter )
소괄호에 파라미터값을 지정해줘야함
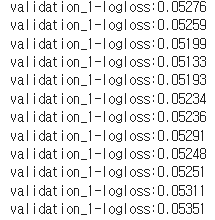
logloss, 손실값이 감소하다 어느순간 증가하는 것을 볼 수 있음
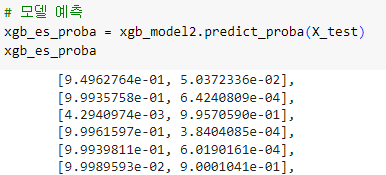
ㅡ 모델 예측 ㅡ
predict_proba ()
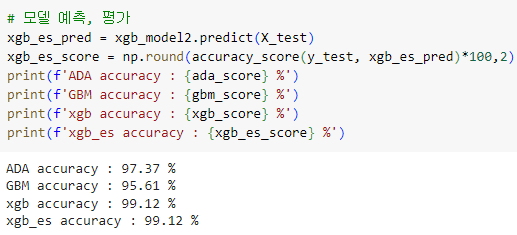
[ 최종 accuracy 결과 ]
Ensemble Boosting

BYE