오늘의 노래 추천 🌙
- 아티스트
- EXO
- 앨범
- LOTTO - The 3rd Album Repackage
- 발매일
- 1970.01.01
할말이 없음 그저 "GOAT" 일뿐 . . . 다들 이 곡의 진가를 알아줬으면 조켓다
DAY 5
[ 타이타닉 생존자 예측 모델 생성 실습 ]
train, test, gender_submission 데이터를 이용해서 생존자 예측 모델 생성하기
test 데이터에는 생존 여부가 없음
ㅡ> 데이터 전처리부터 ML (분류모델) 의 전체 과정을 진행

오늘은 데이터 전처리, EDA 에 집중
[ 1. 문제 정의 ]
[ 2. 데이터 수집 ]

[ 3. 데이터 전처리 ]
[ 4. EDA ]
ㅡ data 불러오기 ㅡ
pd.read_csv
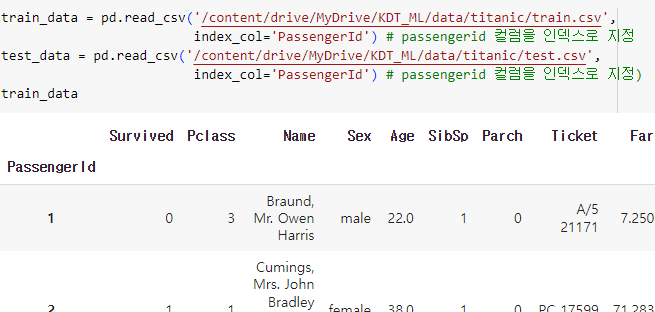
index_col 을 이용해 PassengerId 컬럼을 인덱스(고유 식별자)로 지정
ㅡ data 정보 파악 ㅡ
info ()
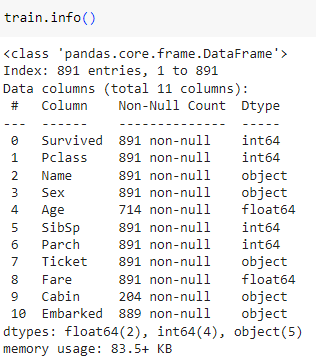
Age, Cabin, Embarked 컬럼의 데이터에 결측,
dtype 을 확인하고 문자데이터를 숫자로 맵핑해줄지 등을 파악
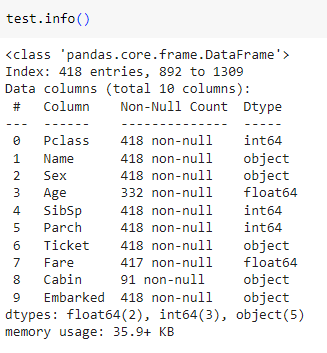
마찬가지로 결측치, dtype 등 정보 확인
ㅡ 컬럼 상관관계를 파악해 결측치 채우기 ㅡ
corr (), select_dtypes ()
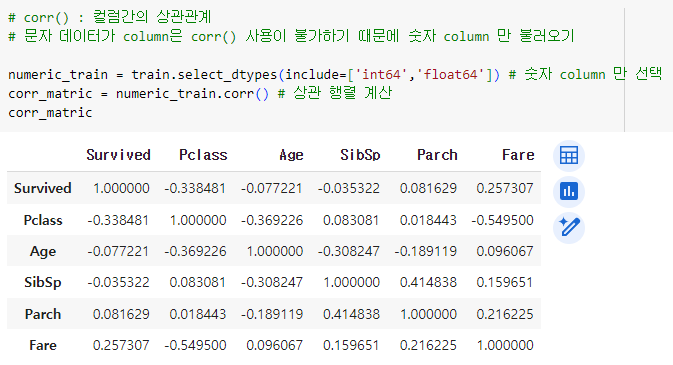
단순 기술 통계치가 아닌 다른 컬럼과의 상관관계를 파악해 결측치 채우기
ㅡ> corr () 를 이용해 컬럼간의 상관관계 파악 (절댓값이 높을수록 상관관계 높음)
ㅡ corr_matric 를 이용해 히트맵 작성 ㅡ
sns.heatmap
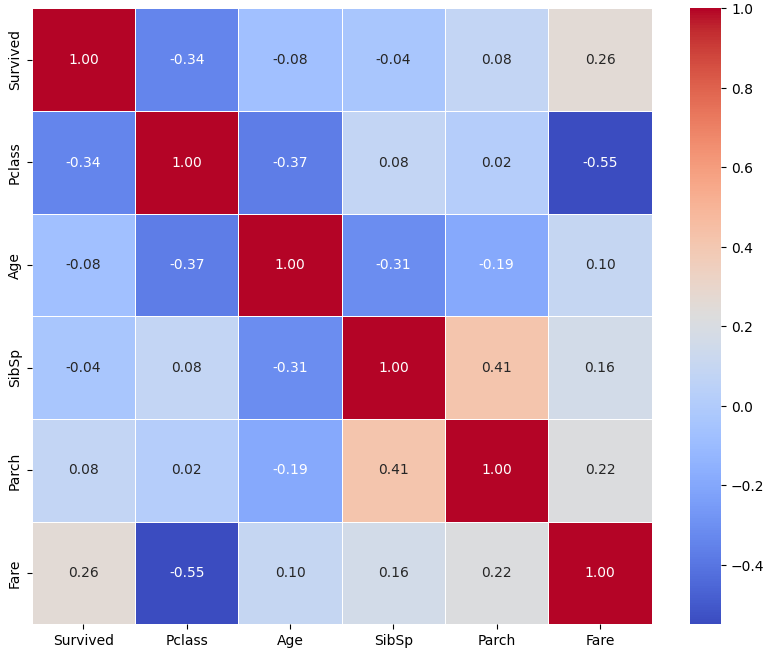
관련성이 높을수록 선명한 색으로 표현
' Pclass ' 가 가장 높은 상관관계를 가짐
ㅡ 상관관계가 높은 column 에 따른 Age 평균 구하기 ㅡ
groupby (), mean ()
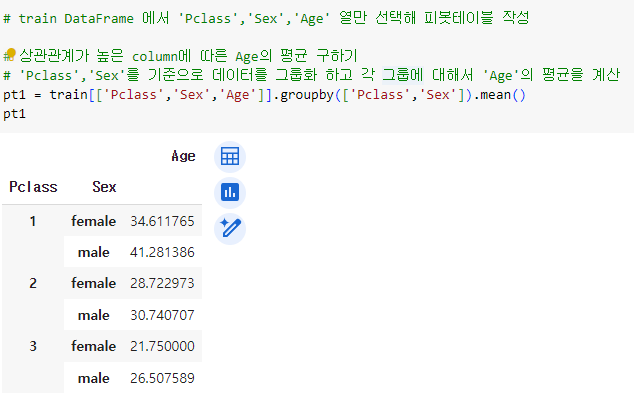
'Pclass', 'Sex' 를 기준으로 데이터를 그룹화 하고
각 그룹에 대해서 'Age' 의 평균을 계산
* 생존에 관련이 많은 것 같은 Sex 컬럼도 그룹핑에 활용
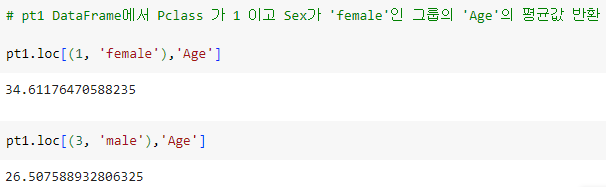
ㅡ Age 가 결측치 (isnan) 일 경우 pt1 의 Age 값을 넣어주는 함수 생성 ㅡ
def, isnan

ㅡ train, test 의 Age 데이터에 fill_age 함수를 적용 ㅡ
apply, astype ()
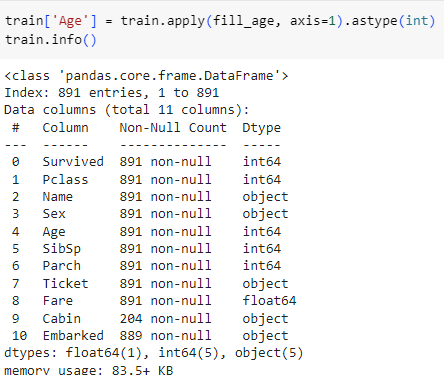
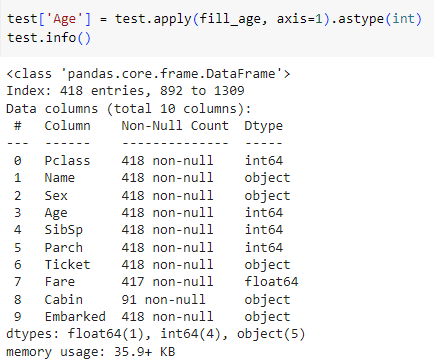
Age 의 결측치가 채워진 것을 볼 수 있음
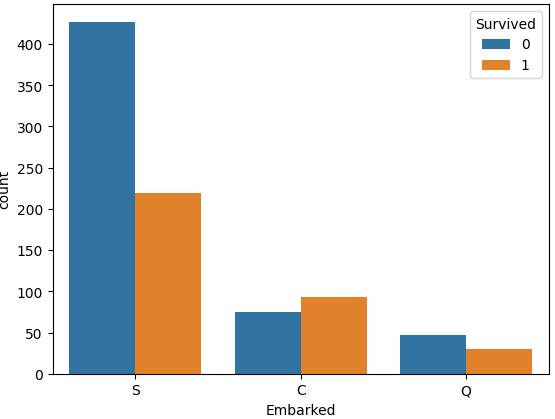
ㅡ Embarked 결측치 채우기 ㅡ
value_counts (), fillna ()
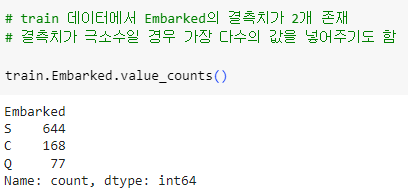
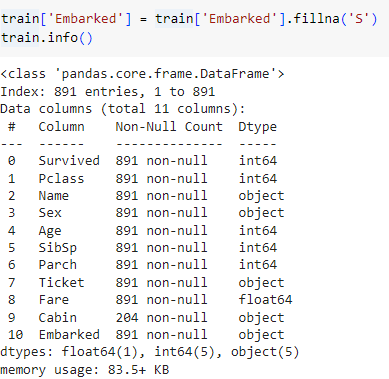
결측치의 데이터가 극소수이므로 가장 다수의 값을 넣어줌
ㅡ 상관관계가 높은 column 에 따른 Fare 평균 구하기 ㅡ
groupby (), mean ()
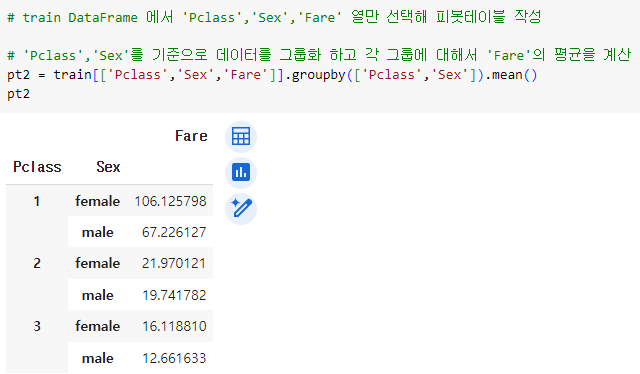
'Pclass', 'Sex' 를 기준으로 데이터를 그룹화 하고
각 그룹에 대해서 'Fare' 의 평균을 계산
* 생존에 관련이 많은 것 같은 Sex 컬럼도 그룹핑에 활용
ㅡ Fare 결측치 채우기 ㅡ
isnull (), fillna ()
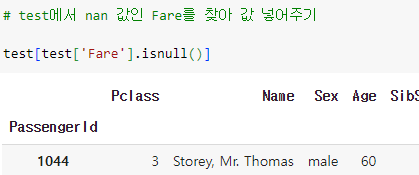
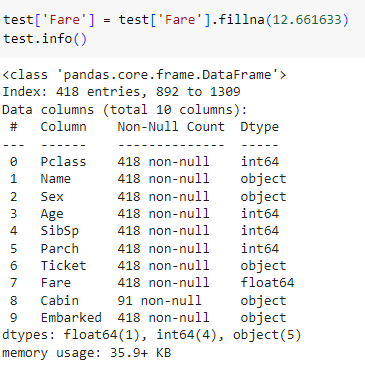
Fare 의 결측치가 1개이기 때문에
nan 인 행의 'Pclass', 'Sex' 정보를 확인하고 직접 값을 넣어줌
ㅡ Cabin 결측치를 채우기 위해 정보 확인 ㅡ
info ()

unique () 값이 너무 다양하므로 그룹화를 진행
ㅡ Cabin 의 값을 그룹화 후 'Deck' 컬럼 생성 ㅡ
fillna (), str []

ㅡ> 결측치는 'M' 으로 기존 값은 첫 번째 문자만 반영해 새 column 인 'Deck'에 저장
ㅡ Cabin 컬럼 삭제 ㅡ
drop ()

column 을 삭제하기 때문에 axis 를 1로 지정해주고 inplace 값을 True 설정
ㅡ 결측치 값 제거 완료 ㅡ
info ()
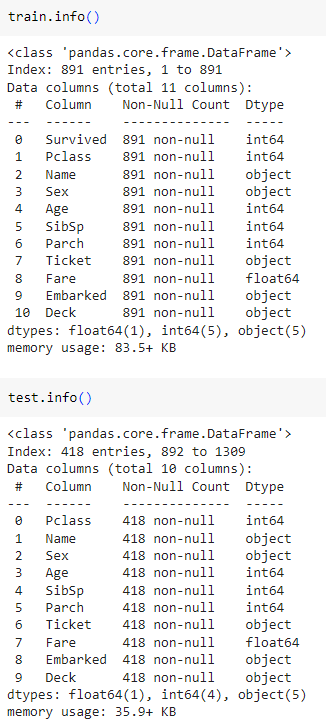
ㅡ 데이터 분석을 위한 "범주형 data" 시각화 진행 ㅡ
info ()

ㅡ 'Deck' 와 'Survived' 값의 관계를 범주화/시각화 ㅡ
groupby (), mean ()

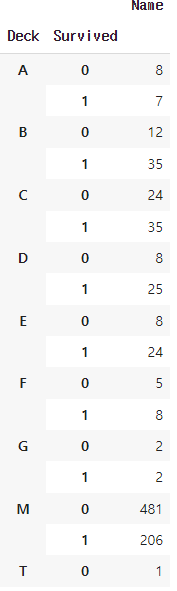
컬럼 내 값이 숫자형이 아니기 때문에 count 함수 사용

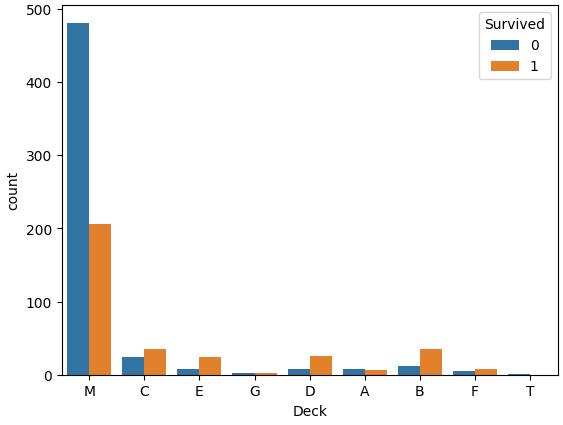
'M' 그룹에서 사망자가 다수임 ㅡ> 생존 여부 예측에 유의미한 지표
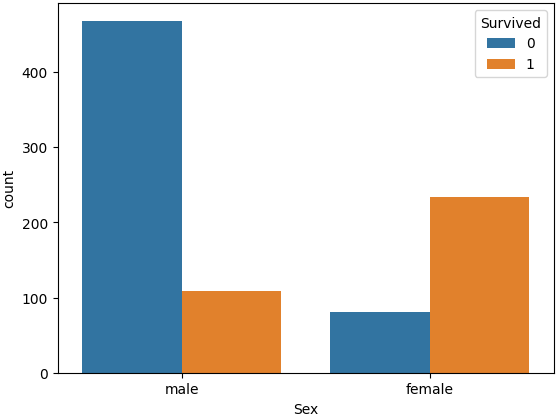
ㅡ 'Pclass' 와 'Survived' 값의 관계를 시각화 ㅡ
sns.countplot

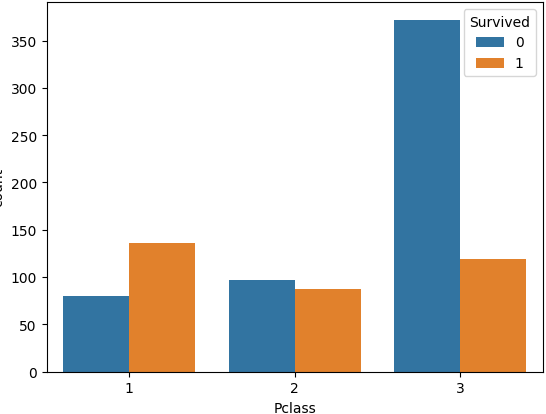
3등급 사망자가 다수임 ㅡ> 유의미한 지표
ㅡ 'Deck' 와 'Pclass' 값의 관계를 시각화 ㅡ
sns.countplot

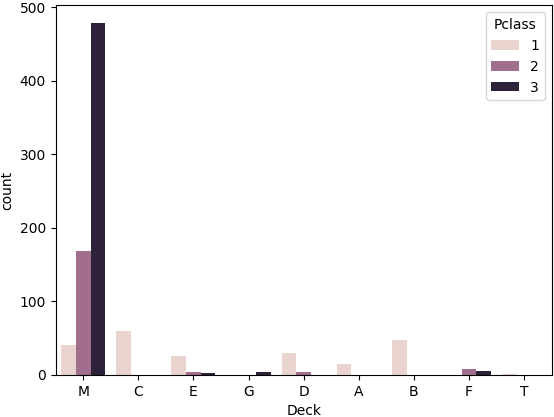
ㅡ 'Deck' 와 'Pclass' 값의 관계를 시각화 ㅡ
sns.countplot

ㅡ 'Deck' 와 'Pclass' 값의 관계를 시각화 ㅡ
sns.countplot

ㅡ 데이터 분석을 위한 "수치형 data" 시각화 진행 ㅡ
info ()

ㅡ Age, Sex 를 기준으로 violinplot 그래프 작성ㅡ
sns.violinplot

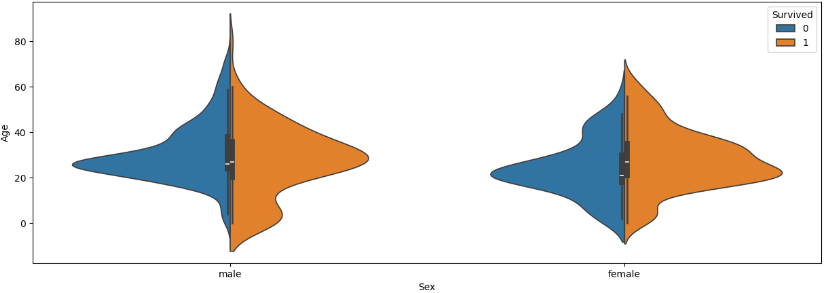
Age 값과 Sex 에 따른 생존 여부를 violinplot 그래프로 시각화
ㅡ> 20~40대 다수 사망, 어린이 중 남아가 비교적 다수 생존
ㅡ Fare, Sex 를 기준으로 violinplot 그래프 작성ㅡ
sns.violinplot
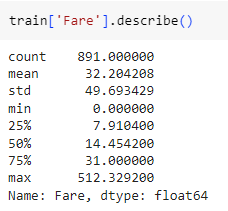
Fare 컬럼 정보 describe

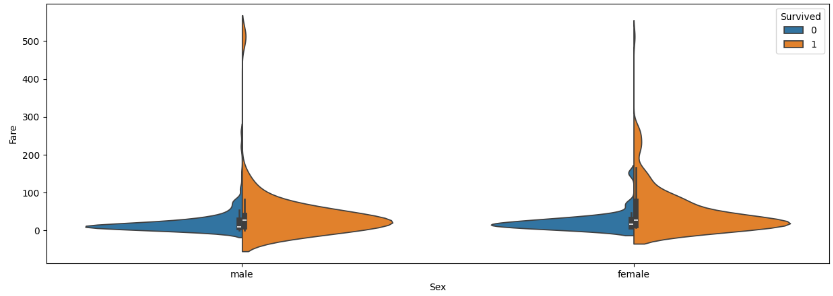
ㅡ> 요금이 낮을수록 상대적으로 사망자 수 증가
ㅡ SibSp + Parch => Family_size 라는 새로운 컬럼 생성ㅡ
컬럼 생성

+ 기호를 사용해 각 컬럼의 값을 더하고 'Family_size' 라는 새 컬럼에 저장
ㅡ Family_size 를 기준으로 countplot 그래프 작성 ㅡ
컬럼 생성
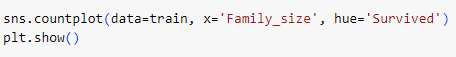
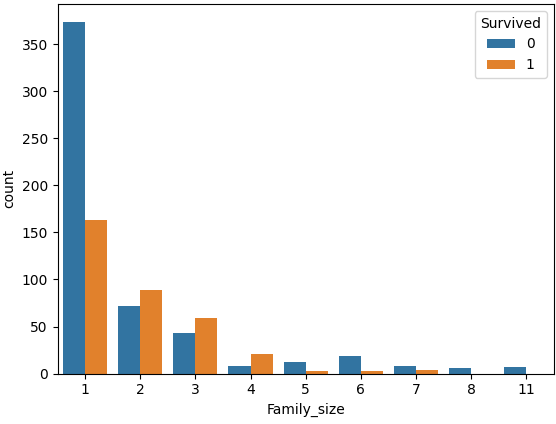
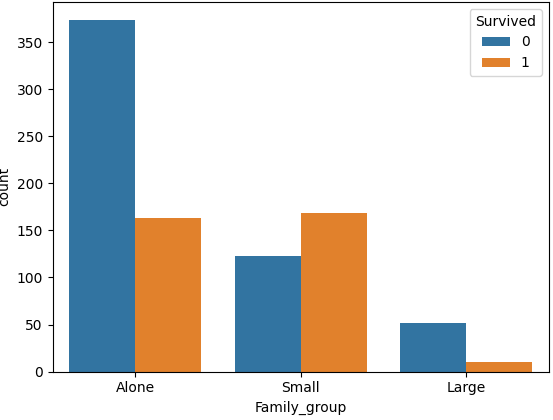
1이거나 5 이상일 때는 생존자 비율이 낮고, 2~4 일때 생존자 비율이 높음
ㅡ> 결과를 기준으로 Family_size 를 한번 더 그룹핑이 가능함 ( S, M, L )
ㅡ Family_size 를 카테고리화 하기 ㅡ
bins, pd.cut ()

Family_size 값에 따라 카테고리화 해주기
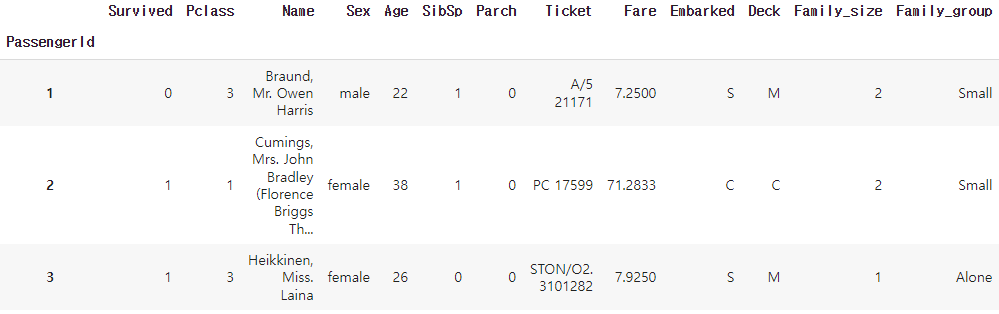
ㅡ 불필요한 column ( Name, Ticket )삭제 ㅡ
drop ()
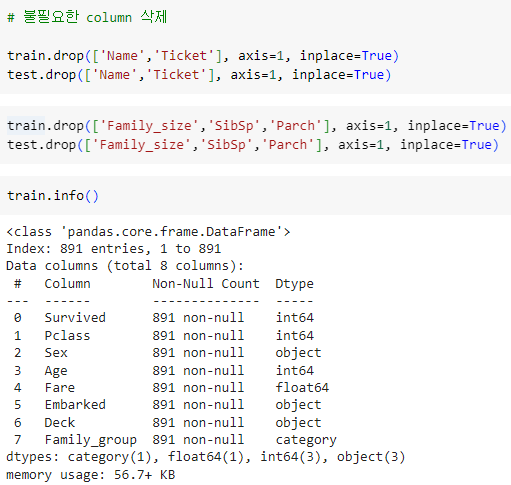
ㅡ 문제, 답지 data 분리 ㅡ
X_train, y_train, X_test

ㅡ 범주형 데이터 One-hot Encoding ㅡ
pd.get_dummies, pd.concat, drop

범주형 데이터 column 만 묶기
범주형 column 데이터를 One-hot Encoding을 통해
수치형 데이터로 변환하기 위함

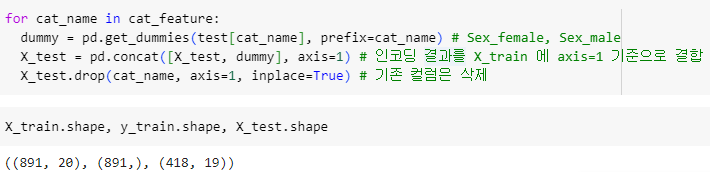
prefix : cat_name ㅡ> 인코딩 진행 후 컬럼에 기존 컬럼명을 접두사로
X_train, X_test 의 컬럼 정보는 일치해야함
ㅡ X_train, X_test 에서 불일치하는 column 정보 찾기 ㅡ
set ()
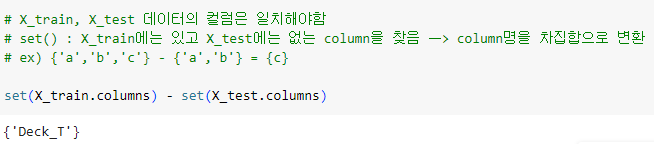
ㅡ 컬럼 정보 일치시키기 ㅡ
Deck_T
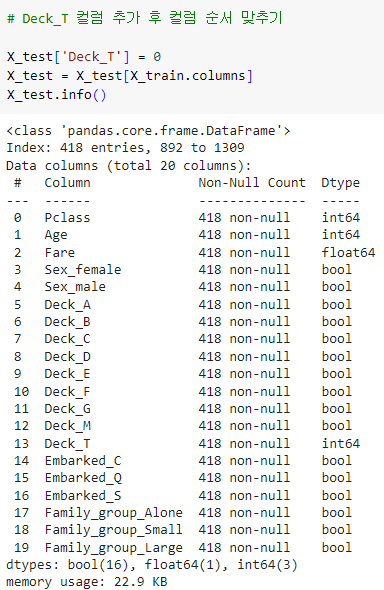
X_test 데이터에 Deck_T 컬럼 추가 후 컬럼 순서 일치
[ 5. 모델 선택 및 학습, 평가 ]
적절한 모델을 선택 생성하고 학습, 평가 진행
ㅡ 적절한 모델을 ㅡ
Deck_T
수정중(미완성)

BYE