오늘의 노래 추천 🎻
- 아티스트
- AJR
- 앨범
- OK ORCHESTRA
- 발매일
- 1970.01.01
오늘은 AJR 느낌 뭐... 아무튼 좋아요 할 말 없긴한데
DAY 3
[ Decision Tree ]
sklearn.tree import
예/아니오 질문을 반복하여 학습
특정 기준에 따라 데이터를 구분
* 분류와 회귀에 모두 사용 가능
Decision Tree 의 의사 결정 방향 ㅡ> 불순도가 낮아지는 방향
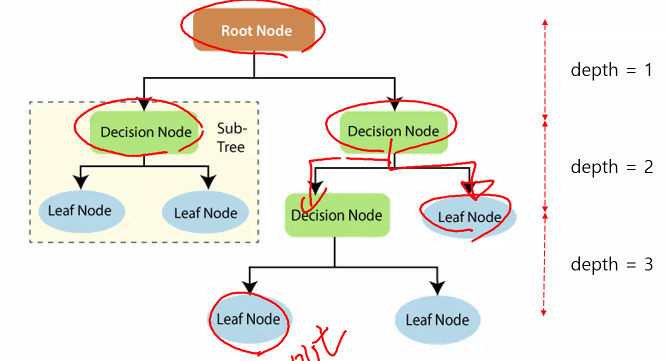
[ 용어 정리 ]
Root Node, Decision Node, Leaf Node, depth, Sub TreeS
ㅡ 불순도 측정 계수 ㅡ
Gini ( 지니 불순도 )
Entropy ( 엔트로피 )
ㅡ 주요 매개변수 (hyperparameter) ㅡ

criterion : 불순도 측정 방법 (gini, entropy)
max_depth : 트리의 최대 깊이
min_samples_split : 노드를 분할하기 위한 최소 샘플 수
min_samples_leaf : 리프 노드가 가져야할 최소 샘플 수
max_leaf_nodes : 리프 노드의 최대 개수
ㅡ 과대 적합 제어 ㅡ

[ Decision Tree 버섯 독/식용 판별 실습 ]
버섯의 특징을 활용해 독/식용 버섯 구분
Decision Tree 시각화 & 과대적합 속성 제어 ( hyper parameter tuning )
특징 선택
ㅡ data 불러오기 ㅡ
pd.read_csv

구글 드라이브에 마운팅 후 pd.read_csv 를 이용해 csv 데이터 불러오기
ㅡ 결측치 확인 ㅡ
info ()
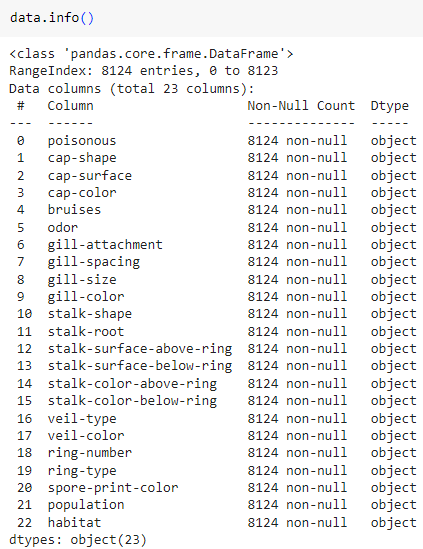
info () 를 이용해 결측치 확인
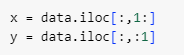
ㅡ x, y로 데이터 분류 ㅡ
iloc

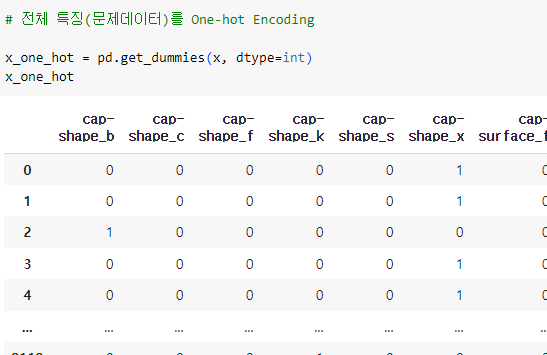
ㅡ 데이터 전처리 ( 원핫인코딩 ) ㅡ
One-hot Encoding
분류하고자 하는 범주만큼의 자릿수(컬럼)를 만들고
단 한개의 1과 나머지는 0으로 채우는 숫자화 방식

pd.get_dummies(X)
ㅡ One-hot Encoding ㅡ
pd.get_dummies ()
* One-hot Encoding 후 변경된 컬럼의 개수는 실행할 때마다 답에 따라 변경됨 (고정값이 아님)
ㅡ 데이터 전처리 ( 라벨 인코딩 ) ㅡ
Label Encoding

x [ '컬럼명' ].map ( { 딕셔너리 형태의 맵핑 } )
레이블을 숫자로 mapping 함
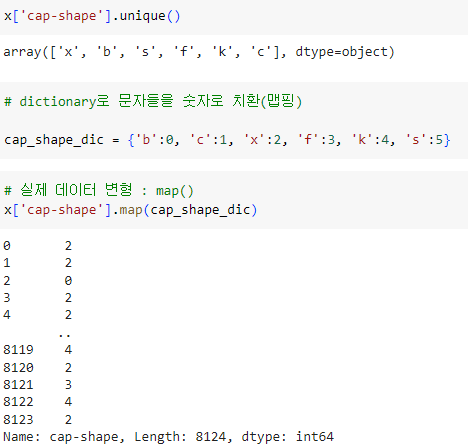
x [ 'cap-shape' ] 의 라벨을 unique 로 알아보고
.map () 함수를 이용해 문자를 숫자로 치환한 mapping 값을 넣어줌
ㅡ 데이터 분할 ㅡ
train_test_split
ㅡ Decision Tree 모델 생성 ㅡ
DecisionTreeClassifier

sklearn.tree 에서 DecisionTreeClassifier 를 import 후 모델 객체 생성
ㅡ 교차 검증 방식 ㅡ
Cross validation
train 과정에서 모델이 데이터 자체를 암기해버릴 경우 과대적합 발생
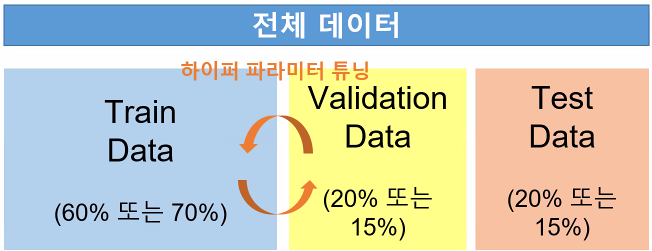
1. train data
2. validation data ( hyper parameter tuning ) ( 모델의 성능 향상 )
3. test data
그러나 과대적합을 피할 수 없음

ㅡ> 검증 data 를 하나로 고정하지 않고 test 데이터의 모든 부분을 사용
각각의 accuracy 의 평균을 구함
[ k-fold cross validation ]
random state
test 데이터를 k개의 그룹으로 분류
k-1 개의 그룹을 모두 학습에 사용
나머지 1개의 그룹으로 평가 수행
k 번 반복 후 accuracy 결과의 평균 구하기
ㅡ 교차 검증 ㅡ
Cross validation

cross_val_score ( 모델명, x_train, y_train, cv =? )
sklearn.model_selection 의 cross_val_score 함수를 불러와 사용

ㅡ 모델 성능 평가 ㅡ
fit, predict, accuracy_score

ㅡ graphviz 라이브러리 설치 ㅡ
!pip stall graphviz


ㅡ 모델 출력파일 생성 ㅡ
export_graphviz
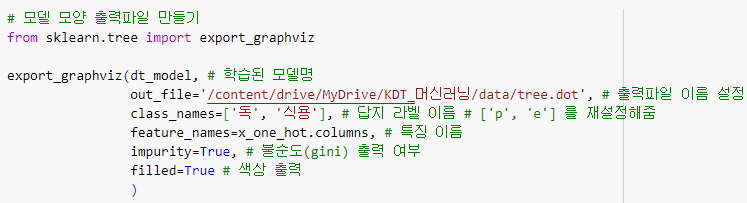
export_graphviz 를 이용해 학습된 모델명을 적고
( out_file ) 파일 경로 마지막에 / tree.dot 을 추가 ㅡ> 출력파일 이름 설정
답지, 라벨명을 설정하고 불순도, 색상 등의 정보 출력 여부를 설정해줌
ㅡ 모델 출력 ㅡ
open

with open ( '파일 경로', 인코딩 ) as f :
dot_graph = f.read ()
그래프 출력 변수를 지정해주고 display ( graphviz.Source ( ) ) 를 이용해 출력
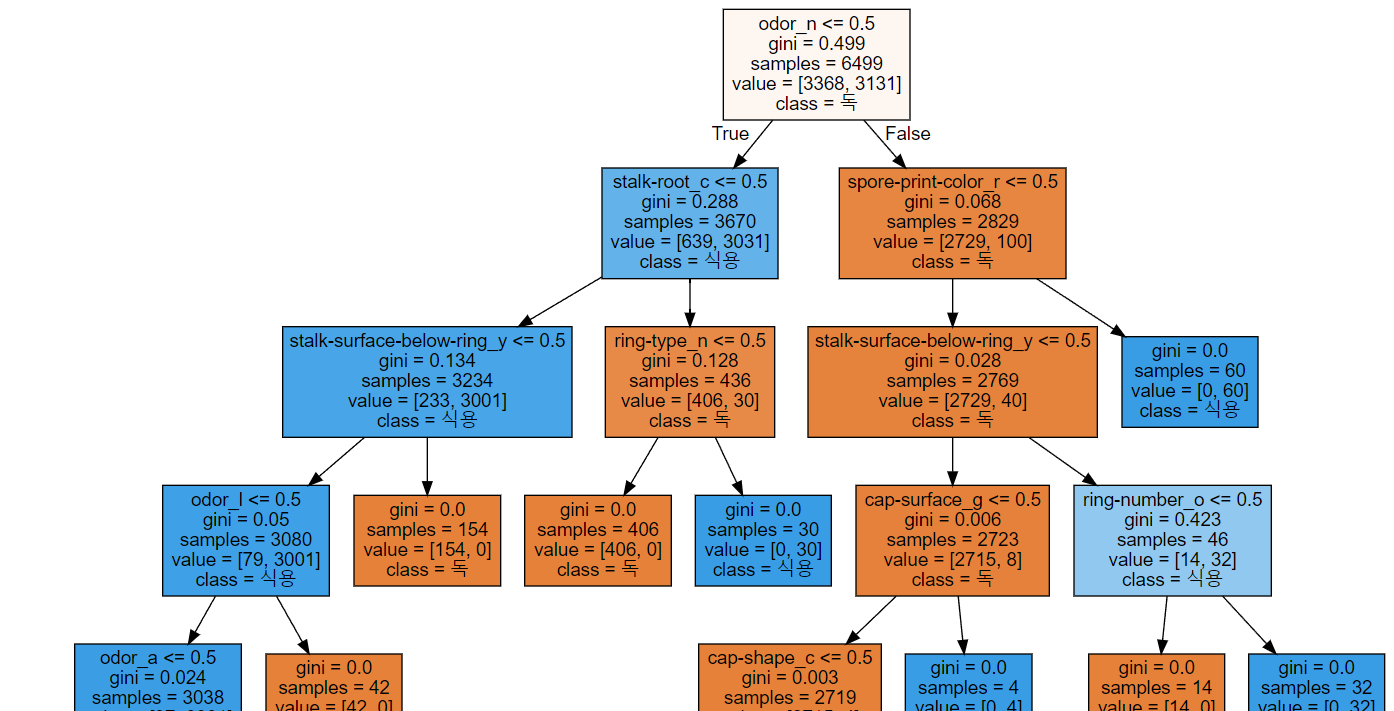
depth 가 높아질수록 gini 계수(불순물)가 낮아짐
[ max-depth 를 이용한 튜닝 ]
max_depth
ㅡ 모델 생성ㅡ
동일하게 모델 생성
ㅡ 모델 출력 파일 생성ㅡ
max_depth 값을 설정
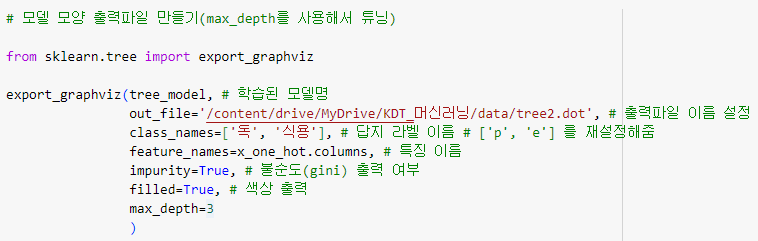
ㅡ 모델 출력 ㅡ
open

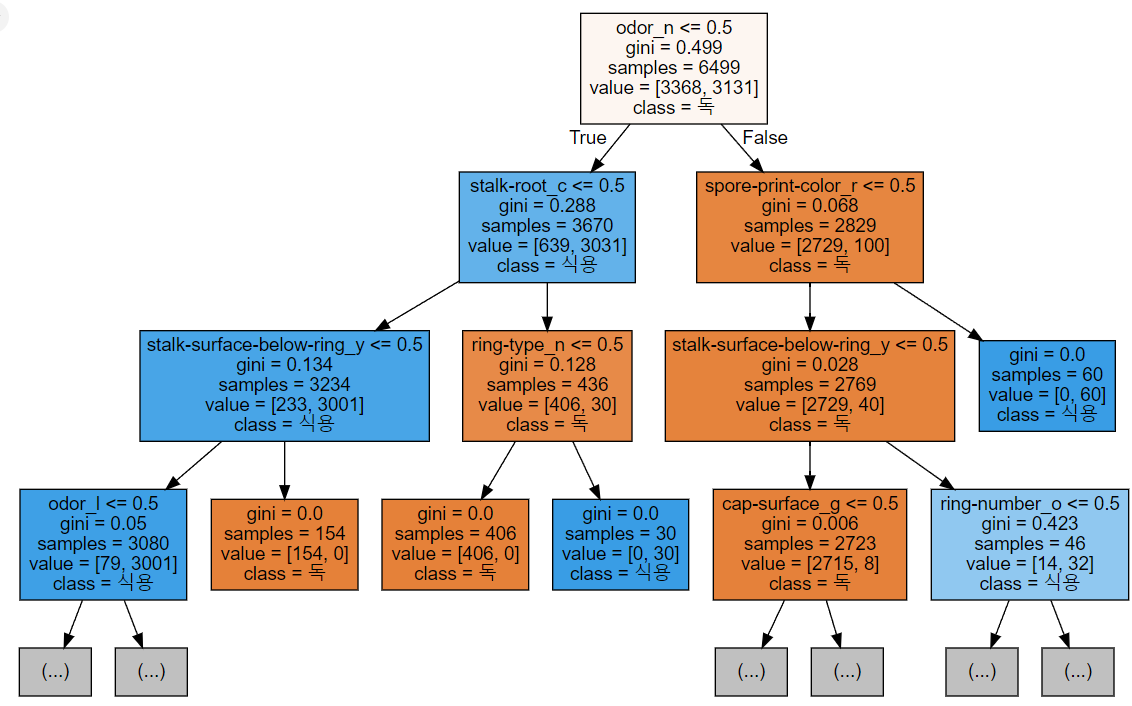
[ 특성 선택 ]
정답(레이블)과 연관 관계가 높은 특성을 선택하는 작업 ( 중요도 파악 )
importance = 모델명.feature_importances_
df = pd.DataFrame(importance, index=x_one_hot.columns, columns=[ '컬럼명' ] )
ㅡ 중요도 부여 ㅡ
feature_importances_

ㅡ DataFrame 생성 후 정렬 ㅡ
pd.DataFrame

index 는 x_one_hot 의 컬럼을 불러오기
중요도를 DataFrame 형태로 만들고 내림차순 정렬 후 출력
ㅡ DataFrame 생성 후 정렬 ㅡ
pd.DataFrame

특성 중요도 순위 top 15을 시리즈로 작성해서 sns.barplot 으로 시각화
[ GirdSerchCV ]
교차검증과 hyper parameter tuning 까지 한번에 수행
sklearn 라이브러리에서 제공하는 모델 성능 개선 함수
사용자가 모델과 hyper parameter 를 지정하면
순차적으로 hyper parameter를 변경해가며 학습과 평가 진행
ㅡ> 가장 성능 좋은 hyper parameter 제시
ㅡ GridSearchCV 과정 ㅡ
GridSearchCV

3x3x3x3 = 81개의 모델 생성 ㅡ> 최적값 제시
ㅡ GridSearchCV import ㅡ
GridSearchCV
ㅡ hyper parameter 값 지정 ㅡ
params ( dictionary 형태 )

ㅡ GridSearchCV 로 모델 설정 ㅡ
GridSearchCV

refit=True 이면 가장 좋은 parameter 값으로 재학습 설정
ㅡ 모델 학습 ㅡ
fit ()

ㅡ 최적의 hyper parameter 값 출력 ㅡ
best_params_, best_score_, best_estimator_

ㅡ 결과 DataFrame 으로 변환 ㅡ
pd.DataFrame

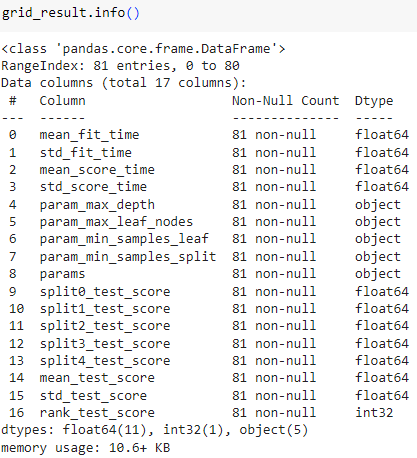
ㅡ 필요한 정보만 뽑아보기 ㅡ
grid_result [ [ ' ' ] ]

ㅡ 'rank_test_score'을 기준으로 정렬 ㅡ
sort_values ( by = '기준컬럼' )

ㅡ 최적 모델 마무리 ㅡ
best_estimator_

ㅡ 최적 모델 생성, 학습, 평가 ㅡ
best_estimator_, fit, score

Label Encoding / One-hot Encoding
Cross validation

BYE