오늘의 노래 추천 🌻
- 아티스트
- 태연 (TAEYEON)
- 앨범
- Purpose - The 2nd Album
- 발매일
- 1970.01.01
저는 여성 솔로 Queen은 태연님이라고 생각하는 편이라서요
- 아티스트
- 태연 (TAEYEON)
- 앨범
- I - The 1st Mini Album
- 발매일
- 1970.01.01
사실 오랜만에 I 마지막 싸비 고음듣고 태연님을 다시 숭배하게됨
DAY 2
[ K-nearest Neighbors ( KNN ) ]
k-최근접 이웃 알고리즘
ㅡ KNN 알고리즘 ㅡ
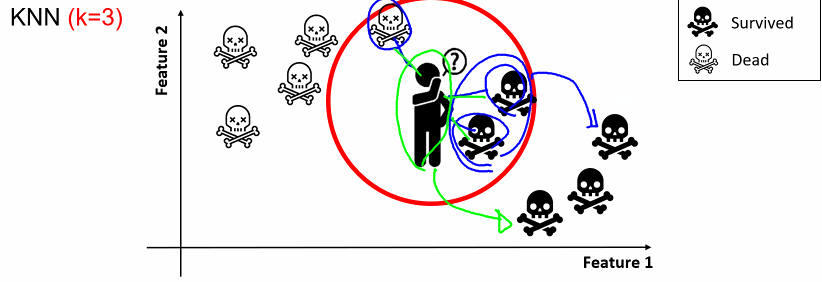

k 값이 작을수록 모델의 복잡도가 상대적으로 증가 ( noise 값에 민감 )
100 개의 데이터를 학습하고 k를 100개로 설정하여 예측하면
빈도가 가장 많은 클래스 레이블로 분류
" 유클리디언 거리 공식 Euclidian "

거리를 측정하기 때문에 같은 scale 을 갖도록 정규화 필요
[ iris 데이터를 이용한 KNN 분류 실습 ]
irid 붓꽃 데이터로 3가지 품종을 분류하는 알고리즘 생성
ㅡ data set 불러오기 ㅡ
sklearn 제공 ( load_ )

ㅡ data key 값 확인 ㅡ
key ()

ㅡ data 전처리 ㅡ
DataFrame
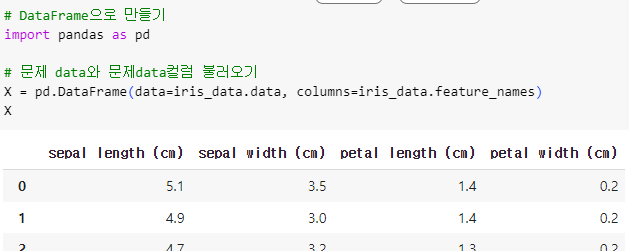
data 전처리를 위해 pandas 를 import 후 DataFrame 형태로 변환해주기
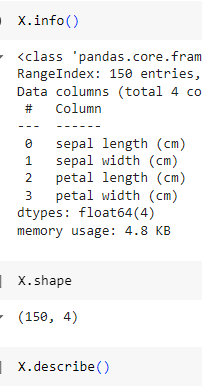
ㅡ data 정보 확인 ㅡ
info (), shape, describe ()
ㅡ EDA 탐색적 데이터 분석 (산점도 그리기) ㅡ
pd.plotting.scatter_matrix ()

데이터 분석을 위한 산점도 그리기
ㅡ 답지(라벨) 데이터 지정 ㅡ
pd.DataFrame
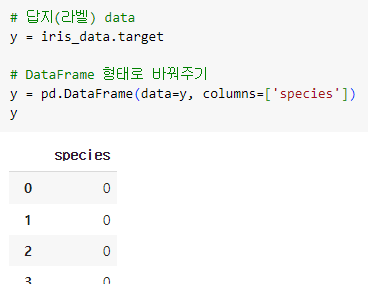
iris_data의 target 컬럼을 답지 데이터로써 y 변수에 넣어주기
ㅡ train, test 데이터 분류 ㅡ
iloc

ㅡ 데이터 분류 결과값이 한쪽으로 편중됨 ㅡ
train_test_split

데이터 편중을 해결하기 위해 sklearn의 train_test_split 이용
ㅡ KNN 모델 생성ㅡ
KNeighborsClassifier
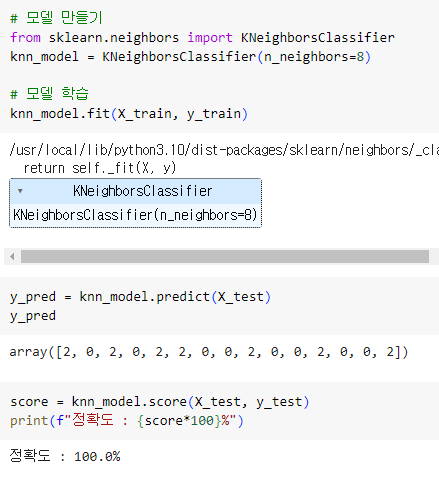
문제 해결 후 KNN 학습 모델 생성을 위해 sklearn.neighbors 에서 KNeighborsClassifier 를 import
fit (), predict (), score() 함수를 이용해 모델학습, 모델 예측, 모델 평가
ㅡ 하이퍼 파라미터 튜닝 ㅡ
hyper parameter

가장 정확도가 우수한 n_neightbors 값을 찾기위한 과정
ㅡ 하이퍼 파라미터 튜닝 ㅡ
hyper parameter

반복문을 활용해 n_neighbors 값을 1~71까지 테스트 후 정확도 결괏값을 리스트에 저장
ㅡ 그래프로 결과 확인ㅡ
plt.plot


[ 당뇨 데이터를 이용한 KNN 분류 실습 ]
당뇨 판별 모델 생성
ㅡ data set 불러오기 ㅡ
sklearn 제공 ( load_ )
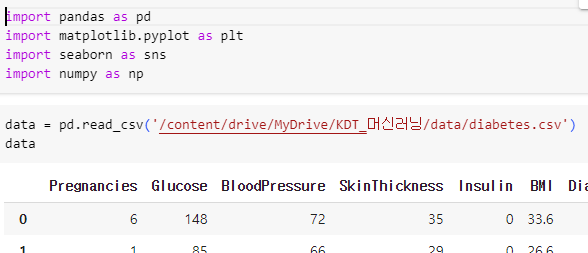
ㅡ data set 정보 확인 ㅡ
keys (), shape, describe ()
ㅡ train, test 데이터 분류 ㅡ
iloc

ㅡ KNN 모델 생성 ㅡ
KNeighborsClassifier
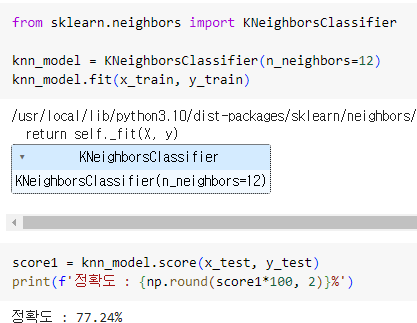
KNeighborsClassifier 을 이용해 모델을 생성하고 학습, 예측, 평가 후 정확도 출력
ㅡ 하이퍼 파라미터 튜닝 ㅡ
hyper parameter tuning

반복문을 이용해 n_neightbors 의 최적값을 구하기 위한 파라미터 튜닝
ㅡ 그래프로 표현 ㅡ
plt.plot


ㅡ score 값 올리기 ㅡ
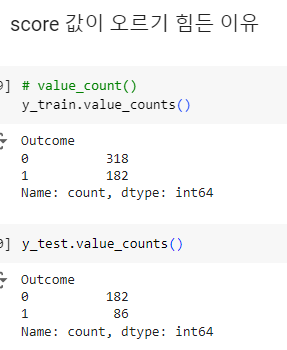
x, y 데이터의 갯수 차이나 y의 결과와 관련업는 x의 컬럼 데이터 등등
score 값이 정확하지 않은 이유는 다양하기 때문에 경우에 따라 조건을 부여해주어야 함
[ Decision Tree ]
sklearn.tree 임포트
예/아니오 질문을 반복하여 학습
특정 기준에 따라 데이터를 구분
* 분류와 회귀에 모두 사용 가능
Decision Tree 의 의사 결정 방향 ㅡ> 불순도가 낮아지는 방향
[ 용어 정리 ]
Root Node, Decision Node, Leaf Node, depth, Sub TreeS

ㅡ 불순도 측정 계수 ㅡ
Gini ( 지니 불순도 )
Entropy ( 엔트로피 )
ㅡ 주요 매개변수 (hyperparameter) ㅡ

criterion : 불순도 측정 방법 (gini, entropy)
max_depth : 트리의 최대 깊이
min_samples_split : 노드를 분할하기 위한 최소 샘플 수
min_samples_leaf : 리프 노드가 가져야할 최소 샘플 수
max_leaf_nodes : 리프 노드의 최대 개수
ㅡ 과대 적합 제어 ㅡ

[ Decision Tree 버섯 독/식용 판별 실습 ]
버섯의 특징을 활용해 독/식용 버섯 구분
Decision Tree 시각화 & 과대적합 속성 제어 ( hyper parameter tuning )
특징 선택
ㅡ data 불러오기 ㅡ
pd.read_csv
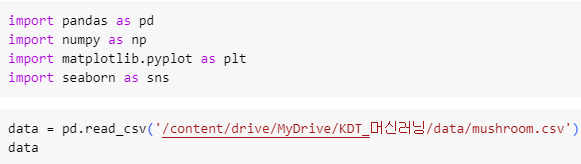
구글 드라이브에 마운팅 후 pd.read_csv 를 이용해 csv 데이터 불러오기
ㅡ 결측치 확인 ㅡ
info ()

info () 를 이용해 결측치 확인
ㅡ x, y로 데이터 분류 ㅡ
iloc
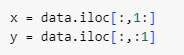

ㅡ 데이터 전처리 ㅡ
One-hot Encoding
분류하고자 하는 범주만큼의 자릿수(컬럼)를 만들고
단 한개의 1과 나머지는 0으로 채우는 숫자화 방식
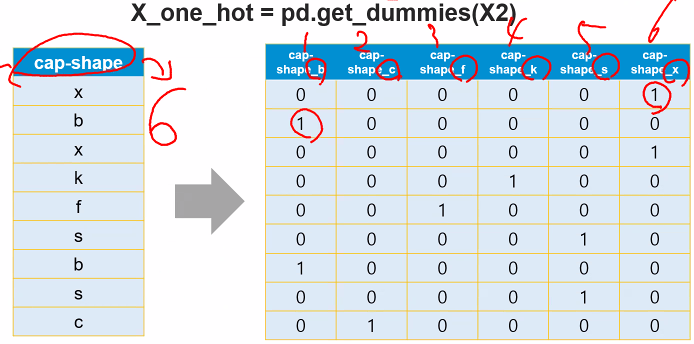
pd.get_dummies(X)
ㅡ One-hot Encoding ㅡ
pd.get_dummies ()

* One-hot Encoding 후 변경된 컬럼의 개수는 실행할 때마다 답에 따라 변경됨 (고정값이 아님)
ㅡ 데이터 분할 ㅡ
train_test_split

ㅡ Decision Tree 모델 생성 ㅡ
DecisionTreeClassifier

sklearn.tree 에서 DecisionTreeClassifier 를 import 후 모델 객체 생성
ㅡ 교차 검증 방식 ㅡ
DecisionTreeClassifier
모델이 데이터 자체를 암기해버릴 경우 과대적합 발생
1. train data
2. validation data ( hyper parameter tuning ) ( 모델의 성능 향상 )
3. test data
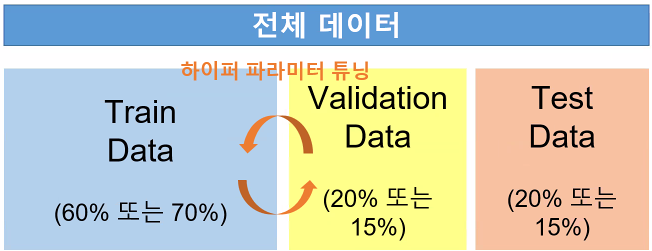
과대적합을 피할 수 없다
ㅡ> 검증 data 를 하나로 고정하지 않고 test 데이터의 모든 부분을 사용
각각의 accuracy 의 평균을 구함
Label Encoding / One-hot Encoding
Cross validation

BYE